数组及其相关 20200825 题目
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 爱丽丝和鲍勃有不同大小的糖果棒:A[i] 是爱丽丝拥有的第 i 块糖的大小,B[j] 是鲍勃拥有的第 j 块糖的大小。 因为他们是朋友,所以他们想交换一个糖果棒,这样交换后,他们都有相同的糖果总量。(一个人拥有的糖果总量是他们拥有的糖果棒大小的总和。) 返回一个整数数组 ans,其中 ans[0] 是爱丽丝必须交换的糖果棒的大小,ans[1] 是 Bob 必须交换的糖果棒的大小。 如果有多个答案,你可以返回其中任何一个。保证答案存在。 示例 1: 输入:A = [1,1], B = [2,2] 输出:[1,2] 示例 2: 输入:A = [1,2], B = [2,3] 输出:[1,2] 示例 3: 输入:A = [2], B = [1,3] 输出:[2,3] 示例 4: 输入:A = [1,2,5], B = [2,4] 输出:[5,4]
官方思路
1 2 3 4 5 6 7 8 9 10 11 12 13 14 class Solution (object) : def fairCandySwap (self, A, B) : Sa, Sb = sum(A), sum(B) setB = set(B) for x in A: if x + (Sb - Sa) / 2 in setB: return [x, x + (Sb - Sa) / 2 ] if __name__ == '__main__' : s = Solution() print(s.fairCandySwap([1 , 1 ], [2 , 2 ])) print(s.fairCandySwap([1 , 2 ], [2 , 3 ])) print(s.fairCandySwap([2 ], [1 , 3 ])) print(s.fairCandySwap([1 , 2 , 5 ], [2 , 4 ]))
题目
1 2 3 4 5 6 7 8 9 给定一个按照升序排列的整数数组 nums,和一个目标值 target。找出给定目标值在数组中的开始位置和结束位置。你的算法时间复杂度必须是 O(log n) 级别。如果数组中不存在目标值,返回 [-1, -1]。 示例 1: 输入: nums = [5,7,7,8,8,10], target = 8 输出: [3,4] 示例 2: 输入: nums = [5,7,7,8,8,10], target = 6 输出: [-1,-1]
思路是我们对 nums 数组从左到右做线性遍历,当遇到 target 时中止。如果我们没有中止过,那么 target 不存在,我们可以返回“错误代码” [-1, -1] 。如果我们找到了有效的左端点坐标,我们可以坐第二遍线性扫描,但这次从右往左进行。这一次,第一个遇到的 target 将是最右边的一个(因为最左边的一个存在,所以一定会有一个最右边的 target)。我们接下来只需要返回这两个坐标。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 class Solution : def searchRange (self, nums, target) : for i in range(len(nums)): if nums[i] == target: left_idx = i break else : return [-1 , -1 ] for j in range(len(nums)-1 , -1 , -1 ): if nums[j] == target: right_idx = j break return [left_idx, right_idx] if __name__ == '__main__' : s = Solution() print(s.searchRange([1 , 0 ], 0 ))
二分法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 class Solution : def extreme_insertion_index (self, nums, target, left) : lo = 0 hi = len(nums) while lo < hi: mid = (lo + hi) // 2 if nums[mid] > target or (left and target == nums[mid]): hi = mid else : lo = mid+1 return lo def searchRange (self, nums, target) : left_idx = self.extreme_insertion_index(nums, target, True ) if left_idx == len(nums) or nums[left_idx] != target: return [-1 , -1 ] return [left_idx, self.extreme_insertion_index(nums, target, False )-1 ]
20200831 题目
1 2 3 4 5 6 7 8 9 10 把一个数组最开始的若干个元素搬到数组的末尾,我们称之为数组的旋转。输入一个递增排序的数组的一个旋转,输出旋转数组的最小元素。例如,数组 [3,4,5,1,2] 为 [1,2,3,4,5] 的一个旋转,该数组的最小值为1。 示例 1: 输入:[3,4,5,1,2] 输出:1 示例 2: 输入:[2,2,2,0,1] 输出:0
旋转数组,就是将一个有序的数组的尾部一部分挪到数组的前面,暴力法:从下标为 0 的元素开始遍历,每次都进行比较,如果当前元素比相邻的下一个元素大,那么就说明下一个元素就是最小值,有一种特殊情况是当数组所有元素都相同时,那么是不会出现上面的这种情况的,那么随便一个元素都是最小值,即取第0个元素即可。
二分法:low 指向数组的第一个元素,high 指向最后一个元素,pivot 为中间元素。因为数组在没有旋转之前是有序的,所以当中间元素 pivot 比右边元素 high 小的时候,说明最小元素在 pivot 或者 pivot 的左边,此时需要移动右指针到 pivot 的位置
当中间元素 pivot 比右边元素 high 大的时候说明最小元素在 pivot 的右边,此时需要移动左指针到 pivot + 1的位置
如果当中间元素 pivot 等于右边元素 high 的时候,那么说明无法判断,这时可以将中间元素往后移动一个位置,然后再次判断,直到左指针等于右指针时,说明找到了最小的元素。
1 2 3 4 5 6 7 8 9 10 11 12 class Solution : def minArray (self, numbers: List[int]) -> int: low, high = 0 , len(numbers) - 1 while low < high: pivot = low + (high - low) // 2 if numbers[pivot] < numbers[high]: high = pivot elif numbers[pivot] > numbers[high]: low = pivot + 1 else : high -= 1 return numbers[low]
栈和队列 题目
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 设计一个支持 push ,pop ,top 操作,并能在常数时间内检索到最小元素的栈。 push(x) —— 将元素 x 推入栈中。 pop() —— 删除栈顶的元素。 top() —— 获取栈顶元素。 getMin() —— 检索栈中的最小元素。 例如 MinStack minStack = new MinStack(); minStack.push(-2); minStack.push(0); minStack.push(-3); minStack.getMin(); --> 返回 -3 minStack.pop(); minStack.top(); --> 返回 0 minStack.getMin(); --> 返回 -2
实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 class MinStack (object) : def __init__ (self) : self.stack = [] // 定义一个栈 def push (self, x) : if not self.stack: // 如果栈为空,那么入栈第一个元素,并且将第一个元素作为最 self.stack.append((x, x)) else : self.stack.append((x, min(x, self.stack[-1 ][1 ]))) def pop (self) : self.stack.pop() def top (self) : return self.stack[-1 ][0 ] def getMin (self) : return self.stack[-1 ][1 ] obj = MinStack() obj.push(1 ) obj.push(-1 ) obj.push(9 ) obj.push(10 ) obj.push(4 ) a = obj.pop() param_3 = obj.top() param_4 = obj.getMin()
题目
1 用两个栈实现一个队列。队列的声明如下,请实现它的两个函数 appendTail 和 deleteHead ,分别完成在队列尾部插入整数和在队列头部删除整数的功能。(若队列中没有元素,deleteHead 操作返回 -1 )
实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 class CQueue : def __init__ (self) : self.in_stack = [] self.out_stack = [] def appendTail (self, value) : self.in_stack.append(value) return value def deleteHead (self) : if self.out_stack: return self.out_stack.pop() else : if not self.in_stack: return -1 else : while (self.in_stack): self.out_stack.append(self.in_stack.pop()) return self.out_stack.pop() if __name__ == '__main__' : c = CQueue() print(c.appendTail(1 )) print(c.appendTail(3 )) print(c.appendTail(5 )) print(c.deleteHead()) print(c.deleteHead()) print(c.deleteHead())
3. 用两个队列实现栈 https://blog.csdn.net/ailunlee/article/details/85100514
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 给定一个只包括 '(',')','{','}','[',']' 的字符串,判断字符串是否有效。 有效字符串需满足:左括号必须用相同类型的右括号闭合。左括号必须以正确的顺序闭合。注意空字符串可被认为是有效字符串。 示例 1: 输入: "()" 输出: true 示例 2: 输入: "()[]{}" 输出: true 示例 3: 输入: "(]" 输出: false 示例 4: 输入: "([)]" 输出: false 示例 5: 输入: "{[]}" 输出: true
利用栈实现,例如要判断的字符串为 {[()]}{} 那么将相反元素入栈,直到栈顶的元素和下一个要判断的元素相同时,那么就进行出栈,如出栈元素和要对比的字符串不一样,那么还是入栈,最后判断栈的大小,栈如果为空,那么就说明全部匹配,否则说明又元素没有匹配。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 class Solution : def isValid (self, s: str) : if len(s) % 2 ==1 : return False stack = [] tmp_map = {"[" : "]" ,"{" :"}" ,"(" :")" } for x in s: if not stack: stack.append(tmp_map.get(x)) continue if x == stack[-1 ]: stack.pop() else : stack.append(tmp_map.get(x)) if stack: return False else : return True if __name__ == '__main__' : c = Solution() print(c.isValid("{}{[]()))}" ))
上面解法判断有问题,可参考图解
1 2 3 4 5 6 给出由小写字母组成的字符串 S,重复项删除操作会选择两个相邻且相同的字母,并删除它们。在 S 上反复执行重复项删除操作,直到无法继续删除。在完成所有重复项删除操作后返回最终的字符串。答案保证唯一。 输入:"abbaca" 输出:"ca" 解释: 例如,在 "abbaca" 中,我们可以删除 "bb" 由于两字母相邻且相同,这是此时唯一可以执行删除操作的重复项。之后我们得到字符串 "aaca",其中又只有 "aa" 可以执行重复项删除操作,所以最后的字符串为 "ca"。
此题也是利用栈来实现,循环字符串,如果栈为空,那么就入栈,否则判断栈顶的元素是否和当前元素相等,如果相等那么就出栈,否则就入栈,最后栈中的剩余元素就是剩下的不相邻的值。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 class Solution : def removeDuplicates (self, s: str) : stack = [] for x in s: if not stack: stack.append(x) continue if stack[-1 ] == x: stack.pop() else : stack.append(x) return "" .join(stack) if __name__ == '__main__' : c = Solution() print(c.removeDuplicates("abbaca" ))
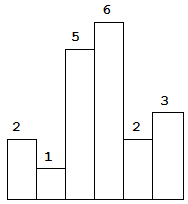
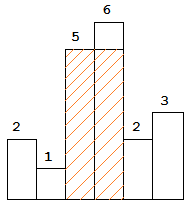
给定 n 个非负整数,用来表示柱状图中各个柱子的高度。每个柱子彼此相邻,且宽度为 1 。
求在该柱状图中,能够勾勒出来的矩形的最大面积。
以上是柱状图的示例,其中每个柱子的宽度为 1,给定的高度为 [2,1,5,6,2,3]。
图中阴影部分为所能勾勒出的最大矩形面积,其面积为 10 个单位。
示例:
1 2 输入: [2,1,5,6,2,3] 输出: 10
图解地址
方法1: 暴力法
方法2: 使用栈
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 给定一个数组 nums,有一个大小为 k 的滑动窗口从数组的最左侧移动到数组的最右侧。你只可以看到在滑动窗口内的 k 个数字。滑动窗口每次只向右移动一位。返回滑动窗口中的最大值。 进阶:你能在线性时间复杂度内解决此题吗? 示例: 输入: nums = [1,3,-1,-3,5,3,6,7], 和 k = 3 输出: [3,3,5,5,6,7] 解释: 滑动窗口的位置 最大值 --------------- ----- [1 3 -1] -3 5 3 6 7 3 1 [3 -1 -3] 5 3 6 7 3 1 3 [-1 -3 5] 3 6 7 5 1 3 -1 [-3 5 3] 6 7 5 1 3 -1 -3 [5 3 6] 7 6 1 3 -1 -3 5 [3 6 7] 7
方法1: 暴力法。每次都求窗口的中的最大值即可
1 2 3 4 5 6 class Solution : def maxSlidingWindow (self, nums: 'List[int]' , k: 'int' ) -> 'List[int]': n = len(nums) if n * k == 0 : return [] return [max(nums[i:i + k]) for i in range(n - k + 1 )]
方法2: 双端队列。图解地址 。步骤细节
1 2 3 4 5 6 7 8 9 10 11 12 13 计你的循环队列实现。 循环队列是一种线性数据结构,其操作表现基于 FIFO(先进先出)原则并且队尾被连接在队首之后以形成一个循环。它也被称为“环形缓冲器”。 循环队列的一个好处是我们可以利用这个队列之前用过的空间。在一个普通队列里,一旦一个队列满了,我们就不能插入下一个元素,即使在队列前面仍有空间。但是使用循环队列,我们能使用这些空间去存储新的值。 你的实现应该支持如下操作: MyCircularQueue(k): 构造器,设置队列长度为 k 。 Front: 从队首获取元素。如果队列为空,返回 -1 。 Rear: 获取队尾元素。如果队列为空,返回 -1 。 enQueue(value): 向循环队列插入一个元素。如果成功插入则返回真。 deQueue(): 从循环队列中删除一个元素。如果成功删除则返回真。 isEmpty(): 检查循环队列是否为空。 isFull(): 检查循环队列是否已满。
方法1: 使用数组 + 双指针。图解地址
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 class MyCircularQueue : def __init__ (self, k: int) : self.front = 0 self.rear = 0 self.capacity = k + 1 self.arr = [0 for _ in range(self.capacity)] def enQueue (self, value: int) -> bool: """ 插入元素。rear 指针往后移动 """ if self.isFull(): return False self.arr[self.rear] = value self.rear = (self.rear + 1 ) % self.capacity return True def deQueue (self) -> bool: """ 删除元素。front 指针往后移动 """ if self.isEmpty(): return False self.front = (self.front + 1 ) % self.capacity return True def Front (self) -> int: """ 获取队首元素 """ if self.isEmpty(): return -1 return self.arr[self.front] def Rear (self) -> int: """ 获取队尾元素 """ if self.isEmpty(): return -1 return self.arr[(self.rear - 1 + self.capacity) % self.capacity] def isEmpty (self) -> bool: """ 当 rear == front 时,认为队列是空的 """ return self.front == self.rear def isFull (self) -> bool: """ 当 rear 在 front 后面一个位置的时候就认为满了。当 rear == front 时,认为队列是空的 """ return (self.rear + 1 ) % self.capacity == self.front
1 2 3 4 5 6 7 8 9 10 11 12 设计实现双端队列。 你的实现需要支持以下操作: MyCircularDeque(k):构造函数,双端队列的大小为k。 insertFront():将一个元素添加到双端队列头部。 如果操作成功返回 true。 insertLast():将一个元素添加到双端队列尾部。如果操作成功返回 true。 deleteFront():从双端队列头部删除一个元素。 如果操作成功返回 true。 deleteLast():从双端队列尾部删除一个元素。如果操作成功返回 true。 getFront():从双端队列头部获得一个元素。如果双端队列为空,返回 -1。 getRear():获得双端队列的最后一个元素。 如果双端队列为空,返回 -1。 isEmpty():检查双端队列是否为空。 isFull():检查双端队列是否满了。
方法1: 数组 + 双指针。和上面类似。图解地址
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 class MyCircularDeque : def __init__ (self, k: int) : self.front = 0 self.rear = 0 self.capacity = k + 1 self.arr = [0 for _ in range(self.capacity)] def insertFront (self, value: int) -> bool: """ 插入元素 """ if self.isFull(): return False self.front = (self.front - 1 + self.capacity) % self.capacity self.arr[self.front] = value return True def insertLast (self, value: int) -> bool: """ 在后面插入元素,rear 指针后移 """ if self.isFull(): return False self.arr[self.rear] = value self.rear = (self.rear + 1 ) % self.capacity return True def deleteFront (self) -> bool: """ 删除前面元素 """ if self.isEmpty(): return False self.front = (self.front + 1 ) % self.capacity return True def deleteLast (self) -> bool: """ 删除后面元素 """ if self.isEmpty(): return False self.rear = (self.rear - 1 + self.capacity) % self.capacity; return True def getFront (self) -> int: """ 获取头元素 """ if self.isEmpty(): return -1 return self.arr[self.front] def getRear (self) -> int: """ 获取尾元素 """ if self.isEmpty(): return -1 return self.arr[(self.rear - 1 + self.capacity) % self.capacity] def isEmpty (self) -> bool: """ 当 rear == front 时,认为队列是空的 """ return self.front == self.rear def isFull (self) -> bool: """ 当 rear 在 front 后面一个位置的时候就认为满了。当 rear == front 时,认为队列是空的 """ return (self.rear + 1 ) % self.capacity == self.front
给定 n 个非负整数表示每个宽度为 1 的柱子的高度图,计算按此排列的柱子,下雨之后能接多少雨水。
1 2 3 4 5 6 7 输入:height = [0,1,0,2,1,0,1,3,2,1,2,1] 输出:6 解释:上面是由数组 [0,1,0,2,1,0,1,3,2,1,2,1] 表示的高度图,在这种情况下,可以接 6 个单位的雨水(蓝色部分表示雨水)。 示例 2: 输入:height = [4,2,0,3,2,5] 输出:9
不会,太难
数组,哈希表 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 给定一个排序数组和一个目标值,在数组中找到目标值,并返回其索引。如果目标值不存在于数组中,返回它将会被按顺序插入的位置。你可以假设数组中无重复元素。 示例 1: 输入: [1,3,5,6], 5 输出: 2 示例 2: 输入: [1,3,5,6], 2 输出: 1 示例 3: 输入: [1,3,5,6], 7 输出: 4 示例 4: 输入: [1,3,5,6], 0 输出: 0
此题可以用二分法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 class Solution : def searchInsert (self, nums, target) : size = len(nums) if size == 0 : return 0 if nums[size - 1 ] < target: return size left, right = 0 , size - 1 while left < right: mid = (left + right) // 2 if nums[mid] < target: left = mid + 1 else : right = mid return left if __name__ == '__main__' : c = Solution() print(c.searchInsert([1 , 3 , 5 , 6 ], 5 ))
1 2 3 4 5 6 7 给你一个数组 nums 和一个值 val,你需要 原地 移除所有数值等于 val 的元素,并返回移除后数组的新长度。不要使用额外的数组空间,你必须仅使用 O(1) 额外空间并 原地 修改输入数组。元素的顺序可以改变。你不需要考虑数组中超出新长度后面的元素。 示例 1: 给定 nums = [3,2,2,3], val = 3, 函数应该返回新的长度 2, 并且 nums 中的前两个元素均为 2。你不需要考虑数组中超出新长度后面的元素。 示例 2: 给定 nums = [0,1,2,2,3,0,4,2], val = 2,函数应该返回新的长度 5, 并且 nums 中的前五个元素为 0, 1, 3, 0, 4。注意这五个元素可为任意顺序。你不需要考虑数组中超出新长度后面的元素。
使用双指针法。慢指针,用于记录有多少不同的元素,如果当前元素的值不等于目标值,那么快慢指针一起向下移动,否则快指针移动,慢指针不移动。快指针移动到元素末尾就结束
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 class Solution : def removeElement (self, nums, target) : j = 0 for i, x in enumerate(nums): if x != target: nums[j] = nums[i] j += 1 print(nums) return j if __name__ == '__main__' : c = Solution() print(c.removeElement([1 , 3 , 5 , 6 , 5 , 7 ], 5 ))
1 2 3 4 5 给定一个排序数组,你需要在原地删除重复出现的元素,使得每个元素只出现一次,返回移除后数组的新长度。不要使用额外的数组空间,你必须在 原地 修改输入数组 并在使用 O(1) 额外空间的条件下完成。 示例 1:给定数组 nums = [1,1,2], 函数应该返回新的长度 2, 并且原数组 nums 的前两个元素被修改为 1, 2。 你不需要考虑数组中超出新长度后面的元素。 示例 2:给定 nums = [0,0,1,1,1,2,2,3,3,4], 函数应该返回新的长度 5, 并且原数组 nums 的前五个元素被修改为 0, 1, 2, 3, 4。你不需要考虑数组中超出新长度后面的元素。
这道题也使用双指针法,和上面类似
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 class Solution : def removeElement (self, nums) : j = 0 for i in range(1 , len(nums)): if nums[j] != nums[i]: j += 1 nums[j] = nums[i] print(nums) print(nums) return j + 1 if __name__ == '__main__' : c = Solution() print(c.removeElement([0 , 0 , 1 , 1 , 1 , 2 , 2 , 3 , 3 , 4 ]))
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 请从字符串中找出一个最长的不包含重复字符的子字符串,计算该最长子字符串的长度。 示例 1: 输入: "abcabcbb" 输出: 3 解释: 因为无重复字符的最长子串是 "abc",所以其长度为 3。 示例 2: 输入: "bbbbb" 输出: 1 解释: 因为无重复字符的最长子串是 "b",所以其长度为 1。 示例 3: 输入: "pwwkew" 输出: 3 解释: 因为无重复字符的最长子串是 "wke",所以其长度为 3。请注意,你的答案必须是 子串 的长度,"pwke" 是一个子序列,不是子串。
方法1:滑动窗口。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 class Solution : def lengthOfLongestSubstring (self, s: str) -> int: head = 0 tail = 0 if len(s) < 2 : return len(s) res = 1 while tail < len(s) - 1 : tail += 1 if s[tail] not in s[head: tail]: res = max(tail - head + 1 , res) else : while s[tail] in s[head: tail]: head += 1 return res
1 2 3 给定一个含有 n 个正整数的数组和一个正整数 s ,找出该数组中满足其和 ≥ s 的长度最小的 连续 子数组,并返回其长度。如果不存在符合条件的子数组,返回 0。 示例:输入:s = 7, nums = [2,3,1,2,4,3] 输出:2 解释:子数组 [4,3] 是该条件下的长度最小的子数组。
这题其实也是双指针的解法,这种解法或者可以称为滑动窗口,两个指针的启示位置分别是 0 和 1,如果两指针之间的值的和加起来不大于目标值,那么就移动前面的指针前移(扩大范围),如果如果两指针之间的值的和加起来大于目标值,那么就移动后面的指针(让其缩小范围)
1 2 3 4 5 6 给定一个正整数 n,生成一个包含 1 到 n 的平方的所有元素,且元素按顺时针顺序螺旋排列的正方形矩阵。 示例:n = 3时,矩阵如下 |1 2 3| |8 9 4| |7 6 5|
思路是定义一个矩阵(二维数组),大小为 n*n,依次从左往右(上边届不变,遍历完成后上边界 + 1),从上到下(右边届不变,遍历完成后右边界 - 1),然后从右往左(下边界不变,遍历完成后下边界 - 1),从下到上遍历(左边界不变,遍历完成后左边界 + 1),直到填充的元素大小大于或者等于 n*n 时,那么就停止循环。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 class Solution : def generateMatrix (self, n: int) -> [[int]]: l, r, t, b = 0 , n - 1 , 0 , n - 1 mat = [[0 for _ in range(n)] for _ in range(n)] num, tar = 1 , n * n while num <= tar: for i in range(l, r + 1 ): mat[t][i] = num num += 1 t += 1 for i in range(t, b + 1 ): mat[i][r] = num num += 1 r -= 1 for i in range(r, l - 1 , -1 ): mat[b][i] = num num += 1 b -= 1 for i in range(b, t - 1 , -1 ): mat[i][l] = num num += 1 l += 1 return mat
1 2 3 4 5 6 7 给定一个整数数组 nums 和一个目标值 target,请你在该数组中找出和为目标值的那 两个 整数,并返回他们的数组下标。你可以假设每种输入只会对应一个答案。但是,数组中同一个元素不能使用两遍。 示例: 给定 nums = [2, 7, 11, 15], target = 9 因为 nums[0] + nums[1] = 2 + 7 = 9 所以返回 [0, 1]
方法1: 暴力枚举。最容易想到的方法是枚举数组中的每一个数 x,寻找数组中是否存在 target - x。
1 2 3 4 5 6 7 8 9 class Solution : def twoSum (self, nums: List[int], target: int) -> List[int]: n = len(nums) for i in range(n): for j in range(i + 1 , n): if nums[i] + nums[j] == target: return [i, j] return []
方法2: 哈希表。创建一个哈希表,对于每一个 x,我们首先查询哈希表中是否存在 target - x,然后将 x 插入到哈希表中,即可保证不会让 x 和自己匹配。
1 2 3 4 5 6 7 8 class Solution : def twoSum (self, nums: List[int], target: int) -> List[int]: hashtable = dict() for i, num in enumerate(nums): if target - num in hashtable: return [hashtable[target - num], i] hashtable[nums[i]] = i return []
7. 三数之和 1 2 3 4 5 6 7 给你一个包含 n 个整数的数组 nums,判断 nums 中是否存在三个元素 a,b,c ,使得 a + b + c = 0 ?请你找出所有满足条件且不重复的三元组。注意:答案中不可以包含重复的三元组。 示例:给定数组 nums = [-1, 0, 1, 2, -1, -4],满足要求的三元组集合为: [ [-1, 0, 1], [-1, -1, 2] ]
方法:先排序,然后使用双指针。图解地址
解题思路是,使用两个指针即双指针法,分别位于输入数组的第一个元素和最后一个元素。比较两个元素的大小,小的一个进行移动,直到两个元素相遇,每移动一次计算一次面积,最后取出最大的面积即可。
核心思想就是矮柱子选取后如果移动高柱子的话面积是一定会减小的,因为长度距离在变小的时候,此时高度只能小于或等于矮的柱子(木桶原理,盛多少水取决于最矮的柱子)。因此只能移动矮的柱子这边才有可能使得高度比矮柱子大。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 from typing import Listclass Solution : def maxArea (self, height: List[int]) -> int: i, j = 0 , len(height) - 1 max_area = 0 while i < j: if height[i] <= height[j]: min_height = height[i] i = i + 1 else : min_height = height[j] j = j - 1 area = (j - i + 1 ) * min_height max_area = max(area, max_area) return max_area if __name__ == '__main__' : s = Solution() print(s.maxArea([1 ,8 ,6 ,2 ,5 ,4 ,8 ,3 ,7 ]))
笨方法就是遍历,计算出所有柱子的所有组合的面积,然后返回最大的,但是这样时间复杂度就是O(n^2)
1 2 3 4 5 6 7 给定一个数组 nums,编写一个函数将所有 0 移动到数组的末尾,同时保持非零元素的相对顺序。 示例: 输入: [0,1,0,3,12] 输出: [1,3,12,0,0] 说明:必须在原数组上操作,不能拷贝额外的数组。尽量减少操作次数。
方法:使用一个指针记录第一个 0 所在的位置,然后让后面非0元素与其交换即可。图解地址
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 假设你正在爬楼梯。需要 n 阶你才能到达楼顶。 每次你可以爬 1 或 2 个台阶。你有多少种不同的方法可以爬到楼顶呢? 注意:给定 n 是一个正整数。 示例 1: 输入: 2 输出: 2 解释: 有两种方法可以爬到楼顶。 1. 1 阶 + 1 阶 2. 2 阶 示例 2: 输入: 3 输出: 3 解释: 有三种方法可以爬到楼顶。 1. 1 阶 + 1 阶 + 1 阶 2. 1 阶 + 2 阶 3. 2 阶 + 1 阶
方法:可以使用递归或者动态规划。动态规划在这里就是斐波那契数列,即 dp[i] = dp[i-2] + dp[i-1]。图解地址 。图解地址2
递归:
1 2 3 4 5 6 class Solution : @functools.lru_cache(100) # 缓存装饰器 def climbStairs (self, n: int) -> int: if n == 1 : return 1 if n == 2 : return 2 return self.climbStairs(n-1 ) + self.climbStairs(n-2 )
斐波那契数列:
1 2 3 4 5 6 7 class Solution : def climbStairs (self, n: int) -> int: if n==1 or n==2 : return n a, b = 1 , 2 for i in range(3 ,n+1 ): a, b = b, a + b return a
1 2 3 4 5 6 7 8 9 10 11 给你两个有序整数数组 nums1 和 nums2,请你将 nums2 合并到 nums1 中,使 nums1 成为一个有序数组。 说明:初始化 nums1 和 nums2 的元素数量分别为 m 和 n 。 你可以假设 nums1 有足够的空间(空间大小大于或等于 m + n)来保存 nums2 中的元素。 示例: 输入: nums1 = [1,2,3,0,0,0], m = 3 nums2 = [2,5,6], n = 3 输出:[1,2,2,3,5,6]
图解地址
方法1: 合并后排序
方法2: 双指针 / 从前往后。这种解法类似于合并两个有序的链表。两个指针分别位于两个数组的头部,每次比较最小的,并且将最小的插入到目标数组中,然后比较小的值的指针后移。
方法3:双指针 / 从后往前。此解法很精妙,可以参考图解地址。和上面正好相反,两个指针分别位于两个数组的尾部,每次比较最大的,并且将并且将最大的插入到目标数组中,然后比较大的值的指针前移。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 class Solution (object) : def merge (self, nums1, m, nums2, n) : p1 = m - 1 p2 = n - 1 p = m + n - 1 while p1 >= 0 and p2 >= 0 : if nums1[p1] < nums2[p2]: nums1[p] = nums2[p2] p2 -= 1 else : nums1[p] = nums1[p1] p1 -= 1 p -= 1 nums1[:p2 + 1 ] = nums2[:p2 + 1 ]
1 2 3 4 5 6 7 8 9 10 11 给定一个由整数组成的非空数组所表示的非负整数,在该数的基础上加一。最高位数字存放在数组的首位, 数组中每个元素只存储单个数字。你可以假设除了整数 0 之外,这个整数不会以零开头。 示例 1: 输入: [1,2,3] 输出: [1,2,4] 解释: 输入数组表示数字 123。 示例 2: 输入: [4,3,2,1] 输出: [4,3,2,2] 解释: 输入数组表示数字 4321。
方法1: 图解地址
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 class Solution : def plusOne (self, digits) : length = len(digits) - 1 for x in range(length + 1 ): digits[length - x] += 1 digits[length - x] %= 10 if digits[length - x] != 0 : return digits digits.insert(0 , 1 ) return digits if __name__ == '__main__' : c = Solution() print(c.plusOne([9 , 9 , 9 ]))
1 2 3 4 5 6 7 8 9 10 11 给定两个字符串 s 和 t ,编写一个函数来判断 t 是否是 s 的字母异位词(字母一样,顺序不一样,字母可以重复)。 示例 1: 输入: s = "anagram", t = "nagaram" 输出: true 示例 2: 输入: s = "rat", t = "car" 输出: false 说明: 你可以假设字符串只包含小写字母。
方法1: 排序。排序后比较是否相同,相同即满足条件
1 2 3 4 5 6 7 class Solution (object) : def isAnagram (self, s, t) : if len(s) != len(t): return False if sorted(s) != sorted(t): return False return True
方法2: 使用哈希表。出现该字母,次数就加一,遍历另一个的是就减一,如果最后不等于0,那么就说明步满足条件。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 class Solution (object) : def isAnagram (self, s, t) : if len(s) != len(t): return False dicts = collections.defaultdict(int) for i in range(len(s)): dicts[s[i]] = dicts[s[i]] + 1 dicts[t[i]] = dicts[t[i]] - 1 for val in dicts.values(): if val != 0 : return False return True
1 2 3 4 5 6 7 8 9 10 给定一个字符串数组,将字母异位词组合在一起。字母异位词指字母相同,但排列不同的字符串。 示例: 输入: ["eat", "tea", "tan", "ate", "nat", "bat"] 输出: [ ["ate","eat","tea"], ["nat","tan"], ["bat"] ]
方法1: 排序数组分类。当且仅当它们的排序字符串相等时,两个字符串是字母异位词。图解地址
1 2 3 4 5 6 class Solution (object) : def groupAnagrams (self, strs) : ans = collections.defaultdict(list) for s in strs: ans[tuple(sorted(s))].append(s) return ans.values()
方法2: 统计单词中字母出现次数,如果次数一样,那么就将他们进行分组。图解地址
1 2 3 4 5 6 7 8 9 class Solution : def groupAnagrams (strs) : ans = collections.defaultdict(list) for s in strs: count = [0 ] * 26 for c in s: count[ord(c) - ord('a' )] += 1 ans[tuple(count)].append(s) return ans.values()
链表 简单 1 2 3 4 5 将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。 示例: 输入:1->2->4, 1->3->4 输出:1->1->2->3->4->4
方法1:递归。定义两个链表 l1 和 l2,如果 l1 或者 l2 一开始就是空链表 ,那么没有任何操作需要合并,所以我们只需要返回非空链表。否则,我们要判断 l1 和 l2 哪一个链表的头节点的值更小,然后递归地决定下一个添加到结果里的节点。如果两个链表有一个为空,递归结束。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 class Solution : def mergeTwoLists (self, l1, l2) : if l1 is None : return l2 elif l2 is None : return l1 elif l1.value < l2.value: l1.next = self.mergeTwoLists(l1.next, l2) return l1 else : l2.next = self.mergeTwoLists(l1, l2.next) return l2
方法2: 迭代。可以用迭代的方法来实现上述算法。当 l1 和 l2 都不是空链表时,判断 l1 和 l2 哪一个链表的头节点的值更小,将较小值的节点添加到结果里,当一个节点被添加到结果里之后,将对应链表中的节点向后移一位。图解地址 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 class Solution : def mergeTwoLists (self, l1, l2) : prehead = ListNode(-1 ) prev = prehead while l1 and l2: if l1.value < l2.value: prev.next = l1 l1 = l1.next else : prev.next = l2 l2 = l2.next prev = prev.next prev.next = l2 if l1 is None else l1 return prehead.next
1 2 3 4 5 6 7 8 9 给定一个排序链表,删除所有重复的元素,使得每个元素只出现一次。 示例 1: 输入: 1->1->2 输出: 1->2 示例 2: 输入: 1->1->2->3->3 输出: 1->2->3
方法1:借助字典,遍历链表存取已经存在的元素,如果之前已经存在,那么就指针直接跳过该元素。
方法2:依次遍历每个元素,对比当前元素和当前元素的下一个元素是否相同,如果相同,那么就使当前元素指向下一个元素的下一个元素。以此来跳过相同的元素。
方法3:双指针。定一个一个临时节点,指针 A 指向临时节点,指针 B 指向临时节点的下一个节点(链表真正的第一个节点),如果 A.value != B.value 那么两者同时往前移动,如果两者相等,那么说明有重复的元素,那么可以将 A 指针停住,B 指针继续往前走,然后继续判断 A.value 和 B.value 的值是否相等。直到两者不相等,那么就 A .next 指向 B,直 B 走到链表末尾。
方法1: 借助字典或者 set,遍历链表存取已经存在的元素,如果之前已经存在,那么就说明有环。
1 2 3 4 5 6 7 8 9 class Solution : def hasCycle (self, head: ListNode) -> bool: seen = set() while head: if head in seen: return True seen.add(head) head = head.next return False
方法2: 使用快慢指针。定义两个指针,慢指针每次移动一步,快指针每次移动两步,如果两个指针相遇,那么就说明有环。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 class Solution : def hasCycle (self, head: ListNode) -> bool: if not head or not head.next: return False slow = head fast = head.next while slow != fast: if not fast or not fast.next: return False slow = slow.next fast = fast.next.next return True
图解地址
方法:双指针法。分别为链表A和链表B设置指针A和指针B,然后开始遍历链表,如果遍历完当前链表,则将指针指向另外一个链表的头部继续遍历,直至两个指针相遇。图解地址
如下代码所示,值得注意的是 ,无论是相交还是不相交,对于无环的链表来说,都一定会相遇,因此不会死循环。(要么在某个点相遇,要么在 null 的时候相遇)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 class Solution : def getIntersectionNode (self, headA, headB) : if not headA or not headB: return None pa, pb = headA, headB while pa != pb: pa = pa.next if pa else headB pb = pb.next if pb else headA return pa
方法2:存链表节点进行查询。遍历链表A,并将其节点存入集合,遍历B的每个节点并在集合中进行查询,一旦遍历过程中查询到相同节点,即说明有交点,否则无
1 2 3 4 5 6 7 8 9 10 11 12 13 class Solution : def getIntersectionNode (self, headA: ListNode, headB: ListNode) -> ListNode: A = set() cur1 = headA cur2 = headB while cur1: A.add(cur1) cur1 = cur1.next while cur2: if cur2 in A: return cur2 cur2 = cur2.next return None
1 2 3 4 5 删除链表中等于给定值 val 的所有节点。 示例: 输入: 1->2->6->3->4->5->6, val = 6 输出: 1->2->3->4->5
方法:在本题中因为是链表是没有顺序的,所以只能一个一个的判断,判断是否为定值 val。需要注意的是需要处理边界值的问题,所以这里引入临时节点。图解地址
反转一个单链表。
1 2 3 4 示例: 输入: 1->2->3->4->5->NULL 输出: 5->4->3->2->1->NULL
方法:双指针。图解地址 , 图解地址2
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 class Solution : def reverseList (self, head: ListNode) -> ListNode: pre = None cur = head while cur: temp = cur.next cur.next = pre pre = cur cur = temp return pre
1 2 3 4 5 6 7 8 9 请判断一个链表是否为回文链表。 示例 1: 输入: 1->2 输出: false 示例 2: 输入: 1->2->2->1 输出: true
中等 1 2 3 4 5 6 7 8 9 10 11 12 13 给定一个链表,两两交换其中相邻的节点,并返回交换后的链表。你不能只是单纯的改变节点内部的值,而是需要实际的进行节点交换。 示例 1: 输入:head = [1,2,3,4] 输出:[2,1,4,3] 示例 2: 输入:head = [] 输出:[] 示例 3: 输入:head = [1] 输出:[1]
方法1:可以使用栈,将两两元素入栈,出栈后即交换了顺序。图解地址
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 class Solution (object) : def swapPairs (self, head) : if not (head and head.next): return head p = ListNode(-1 ) cur,head,stack = head,p,[] while cur and cur.next: _,_ = stack.append(cur),stack.append(cur.next) cur = cur.next.next p.next = stack.pop() p.next.next = stack.pop() p = p.next.next if cur: p.next = cur else : p.next = None return head.next
方法2: 迭代实现。图解地址
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 class Solution (object) : def swapPairs (self, head) : p = ListNode(-1 ) a,b,p.next,tmp = p,p,head,p while b.next and b.next.next: a,b = a.next,b.next.next tmp.next,a.next,b.next = b,b.next,a tmp,b = a,a return p.next
树 1 2 3 4 5 6 7 8 9 10 11 12 13 给定一个二叉树,返回它的中序 遍历。 示例: 输入: [1,null,2,3] 1 \ 2 / 3 输出: [1,3,2] 进阶: 递归算法很简单,你可以通过迭代算法完成吗?
方法1: 递归 图解地址
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 class Solution : def inorderTraversal (self, root: TreeNode) -> List[int]: res = [] if not root: return back_func(root.left) res.append(root.val) back_func(root.right) return res
方法2: 栈 图解地址
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 class Solution : def inorderTraversal (self, root: TreeNode) -> List[int]: if not root: return [] stack, res = [root], [] while stack: while root.left: stack.append(root.left) root = root.left cur = stack.pop() res.append(cur.val) if cur.right: stack.append(cur.right) root = cur.right return res
1 2 3 4 5 6 7 8 9 10 11 12 13 给定一个二叉树,返回它的 前序 遍历。 示例: 输入: [1,null,2,3] 1 \ 2 / 3 输出: [1,2,3] 进阶: 递归算法很简单,你可以通过迭代算法完成吗?
方法1: 递归 图解地址
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 class Solution : def inorderTraversal (self, root: TreeNode) -> List[int]: res = [] if not root: return res.append(root.val) back_func(root.left) back_func(root.right) return res
方法2: 迭代 图解地址
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 class Solution (object) : def preorderTraversal (self, root) : if root is None : return [] stack, res = [root], [] while stack: root = stack.pop() if root is not None : res.append(root.val) if root.right is not None : stack.append(root.right) if root.left is not None : stack.append(root.left) return res
1 2 3 4 5 6 7 8 9 10 11 12 13 给定一个二叉树,返回它的 后序 遍历。 示例: 输入: [1,null,2,3] 1 \ 2 / 3 输出: [3,2,1] 进阶: 递归算法很简单,你可以通过迭代算法完成吗?
方法1: 递归 图解地址
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 class Solution : def inorderTraversal (self, root: TreeNode) -> List[int]: res = [] if not root: return back_func(root.left) back_func(root.right) res.append(root.val) return res
方法2: 栈 图解地址
先看后序遍历的顺序, 左右中。
前序是,中左右
所以后续反转是,中右左。和前序相比,只是左右位置改变了
所以思路是在前序遍历中,把left 和 right的顺序调换,然后输出反转的树即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 class Solution (object) : def postorderTraversal (self, root) : if root is None : return [] stack, res = [root], [] while stack: root = stack.pop() if root is not None : res.append(root.val) if root.left is not None : stack.append(root.left) if root.right is not None : stack.append(root.right) return res[::-1 ]
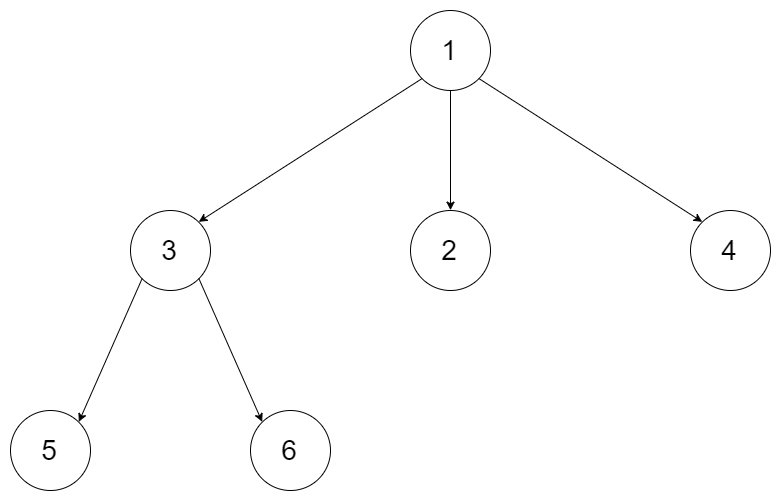
给定一个 N 叉树,返回其节点值的前序遍历 。
例如,给定一个 3叉树 :
返回其前序遍历: [1,3,5,6,2,4]。说明: 递归法很简单,你可以使用迭代法完成此题吗?
方法1: 递归,先处理根节点,再对当前节点的所有子节点递归进行前序遍历。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 """ class Node: def __init__(self, val=None, children=None): self.val = val self.children = children """ class Solution : def preorder (self, root: 'Node' ) -> List[int]: if not root: return [] res = [root.val] for node in root.children: res += self.preorder(node) return res
方法2: 栈
1 2 3 4 5 6 7 8 9 10 11 12 13 class Solution (object) : def preorder (self, root) : if root is None : return [] stack, output = [root, ], [] while stack: root = stack.pop() if root is not None : output.append(root.val) stack.extend(root.children[::-1 ]) return output
给定一个 N 叉树,返回其节点值的后序遍历 。
例如,给定一个 3叉树 :
返回其后序遍历: [5,6,3,2,4,1].说明: 递归法很简单,你可以使用迭代法完成此题吗?
方法1: 递归,先对当前节点的所有子节点递归进行后序遍历,后处理根节点
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 """ class Node: def __init__(self, val=None, children=None): self.val = val self.children = children """ class Solution : def postorder (self, root: 'Node' ) -> List[int]: res = [] if not root: return [] for node in root.children: res.extend(self.postorder(node)) res.append(root.val) return res
方法2: 迭代
1 2 3 4 5 6 7 8 9 10 11 12 13 class Solution (object) : def postorder (self, root) : if root is None : return [] stack, output = [root, ], [] while stack: root = stack.pop() if root is not None : output.append(root.val) stack.extend(root.children) return output[::-1 ]
1 2 3 4 5 6 7 8 9 10 11 数字 n 代表生成括号的对数,请你设计一个函数,用于能够生成所有可能的并且 有效的 括号组合。 示例: 输入:n = 3 输出:[ "((()))", "(()())", "(())()", "()(())", "()()()" ]
方法1: 递归。n 等于3,说明括号有3对,也就是6个,且满足的有效的括号的话,那么左括号 = 右括号 = 3,如果当前左括号的个数已经小于右括号的个数了【例如 (())) 】,那么说明已经不能在组合成有效的括号了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 from typing import Listclass Solution : def generateParenthesis (self, n: int) -> List[str]: res = [] cur_str = '' def dfs (cur_str, left, right, n) : """ :param cur_str: 从根结点到叶子结点的路径字符串 :param left: 左括号已经使用的个数 :param right: 右括号已经使用的个数 :return: """ if left == n and right == n: res.append(cur_str) return if left < right: return if left < n: dfs(cur_str + '(' , left + 1 , right, n) if right < n: dfs(cur_str + ')' , left, right + 1 , n) dfs(cur_str, 0 , 0 , n) return res
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 翻转一棵二叉树。 示例: 输入: 4 / \ 2 7 / \ / \ 1 3 6 9 输出: 4 / \ 7 2 / \ / \ 9 6 3 1
方法1: 递归。交换当前节点的左右子树,然后在递归交换当前节点的 左子树和右子树
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 class Solution (object) : def invertTree (self, root) : """ :type root: TreeNode :rtype: TreeNode """ if not root: return None root.left,root.right = root.right,root.left self.invertTree(root.left) self.invertTree(root.right) return root
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 给定一个二叉树,判断其是否是一个有效的二叉搜索树。假设一个二叉搜索树具有如下特征: 节点的左子树只包含小于当前节点的数。 节点的右子树只包含大于当前节点的数。 所有左子树和右子树自身必须也是二叉搜索树。 示例 1: 输入: 2 / \ 1 3 输出: true 示例 2: 输入: 5 / \ 1 4 / \ 3 6 输出: false 解释: 输入为: [5,1,4,null,null,3,6]。根节点的值为 5 ,但是其右子节点值为 4 。
方法1: 中序遍历。根据二叉搜索树的性质,中序遍历的结果是一个递增的值,只需要在遍历过程中判断当前值是否大于前一个值即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 class Solution : def isValidBST (self, root) : """ :type root: TreeNode :rtype: bool """ stack, inorder = [], float('-inf' ) while stack or root: while root: stack.append(root) root = root.left root = stack.pop() if root.val <= inorder: return False inorder = root.val root = root.right return True
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 输入一棵二叉树的根节点,判断该树是不是平衡二叉树。如果某二叉树中任意节点的左右子树的深度相差不超过1,那么它就是一棵平衡二叉树。 示例 1: 给定二叉树 [3,9,20,null,null,15,7] 3 / \ 9 20 / \ 15 7 返回 true 。 示例 2: 给定二叉树 [1,2,2,3,3,null,null,4,4] 1 / \ 2 2 / \ 3 3 / \ 4 4 返回 false 。
方法:递归,判断每个节点的左右子树的深度不超过1即可。
1 2 3 4 5 6 7 8 9 class Solution : def isBalanced (self, root: TreeNode) -> bool: if not root: return True return abs(self.depth(root.left) - self.depth(root.right)) <= 1 and \ self.isBalanced(root.left) and self.isBalanced(root.right) def depth (self, root) : if not root: return 0 return max(self.depth(root.left), self.depth(root.right)) + 1
1 2 3 4 5 6 7 8 9 10 11 12 13 给定一个二叉树,找出其最大深度。二叉树的深度为根节点到最远叶子节点的最长路径上的节点数。 说明: 叶子节点是指没有子节点的节点。 示例: 给定二叉树 [3,9,20,null,null,15,7], 3 / \ 9 20 / \ 15 7 返回它的最大深度 3 。
方法1: 递归。分别求左右子树的高度,然后在取最大值 + 1
1 2 3 4 5 6 7 8 class Solution : def maxDepth (self, root) : if root is None : return 0 else : left_height = self.maxDepth(root.left) right_height = self.maxDepth(root.right) return max(left_height, right_height) + 1
1 2 3 4 5 6 7 8 9 10 给定一个二叉树,找出其最小深度。最小深度是从根节点到最近叶子节点的最短路径上的节点数量。说明: 叶子节点是指没有子节点的节点。 示例:给定二叉树 [3,9,20,null,null,15,7], 3 / \ 9 20 / \ 15 7 返回它的最小深度
方法1: 递归。
1 2 3 4 5 6 7 8 9 10 class Solution : def minDepth (self, root: TreeNode) -> int: if not root: return 0 l, r = self.minDepth(root.left), self.minDepth(root.right) if root.left and root.right: return 1 + min(l, r) else : return 1 + l + r
11. 树的广度优先遍历 利用队列我们只要在节点出队的时候让该节点的子节点入队即可
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 class Queue () : def __init__ (self) : self.__list = list() def isEmpty (self) : return self.__list == [] def push (self, data) : self.__list.append(data) def pop (self) : if self.isEmpty(): return False return self.__list.pop(0 ) def breadthFirst (tree) : queue = Queue() queue.push(tree) result = [] while not queue.isEmpty(): node = queue.pop() result.append(node.data) for c in node.getChildren(): queue.push(c) return result
12. 树的深度优先遍历 实现深度优先遍历,我们只要在节点出栈的时候把该节点的子节点从左到右压入堆栈即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 class Stack () : def __init__ (self) : self.__list = list() def isEmpty (self) : return self.__list == [] def push (self, data) : self.__list.append(data) def pop (self) : if self.isEmpty(): return False return self.__list.pop() def depthFirst (tree) : stack = Stack() stack.push(tree) result = [] while not stack.isEmpty(): node = stack.pop() result.append(node.data) children = node.getChildren() children = reversed(children) for c in children: stack.push(c) return result
递归 1 2 3 4 5 6 7 8 9 10 11 12 13 14 实现 pow(x, n) ,即计算 x 的 n 次幂函数。 示例 1: 输入: 2.00000, 10 输出: 1024.00000 示例 2: 输入: 2.10000, 3 输出: 9.26100 示例 3: 输入: 2.00000, -2 输出: 0.25000 解释: 2^-2 = 1/2^2 = 1/4 = 0.25
方法1: 递归。例 2^10 可以看成 2^5 2^5。如果是 2^9, 那么可以看成 2^4 2^4 * 2
1 2 3 4 5 6 7 8 9 class Solution : def myPow (self, x: float, n: int) -> float: def quickMul (N) : if N == 0 : return 1.0 y = quickMul(N // 2 ) return y * y if N % 2 == 0 else y * y * x return quickMul(n) if n >= 0 else 1.0 / quickMul(-n)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 给定一组不含重复元素的整数数组 nums,返回该数组所有可能的子集(幂集)。说明:解集不能包含重复的子集。 示例: 输入: nums = [1,2,3] 输出: [ [3], [1], [2], [1,2,3], [1,3], [2,3], [1,2], [] ]
方法:回溯。难
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 class Solution public List<List<Integer>> subsets(int [] nums) { List<List<Integer>> res = new ArrayList<>(); backtrack(0 , nums, res, new ArrayList<Integer>()); return res; } private void backtrack (int i, int [] nums, List<List<Integer>> res, ArrayList<Integer> tmp) res.add(new ArrayList<>(tmp)); for (int j = i; j < nums.length; j++) { tmp.add(nums[j]); backtrack(j + 1 , nums, res, tmp); tmp.remove(tmp.size() - 1 ); } } }
1 2 3 4 5 6 7 8 9 给定一个大小为 n 的数组,找到其中的多数元素。多数元素是指在数组中出现次数大于 ⌊ n/2 ⌋ 的元素。你可以假设数组是非空的,并且给定的数组总是存在多数元素。 示例 1: 输入: [3,2,3] 输出: 3 示例 2: 输入: [2,2,1,1,1,2,2] 输出: 2
方法1: 哈希表
1 2 3 4 class Solution : def majorityElement (self, nums) : counts = collections.Counter(nums) return max(counts.keys(), key=counts.get)
方法2: 排序。取排序后中间位置的元素,因为题目说一定存在,所以不管是奇数个还是偶数个,中间的一定是出现最多的。
1 2 3 4 class Solution : def majorityElement (self, nums) : nums.sort() return nums[len(nums) // 2 ]
贪心 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 在柠檬水摊上,每一杯柠檬水的售价为 5 美元。顾客排队购买你的产品,(按账单 bills 支付的顺序)一次购买一杯。每位顾客只买一杯柠檬水,然后向你付 5 美元、10 美元或 20 美元。你必须给每个顾客正确找零,也就是说净交易是每位顾客向你支付 5 美元。注意,一开始你手头没有任何零钱。如果你能给每位顾客正确找零,返回 true ,否则返回 false 示例 1: 输入:[5,5,5,10,20] 输出:true 解释: 前 3 位顾客那里,我们按顺序收取 3 张 5 美元的钞票。第 4 位顾客那里,我们收取一张 10 美元的钞票,并返还 5 美元。第 5 位顾客那里,我们找还一张 10 美元的钞票和一张 5 美元的钞票。由于所有客户都得到了正确的找零,所以我们输出 true。 示例 2: 输入:[5,5,10] 输出:true 示例 3: 输入:[10,10] 输出:false 示例 4: 输入:[5,5,10,10,20] 输出:false 解释: 前 2 位顾客那里,我们按顺序收取 2 张 5 美元的钞票。对于接下来的 2 位顾客,我们收取一张 10 美元的钞票,然后返还 5 美元。对于最后一位顾客,我们无法退回 15 美元,因为我们现在只有两张 10 美元的钞票。由于不是每位顾客都得到了正确的找零,所以答案是 false。
方法: 贪心。给 20 找零的时候,优先使用 10 + 5 的选择,如果没有在使用 3 张5元。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 class Solution : def lemonadeChange (self, bills: List[int]) -> bool: Hash = {} for bill in bills: if bill == 5 : Hash[bill] = Hash.get(bill, 0 ) + 1 elif bill == 10 : if Hash.get(5 , 0 ) > 0 : Hash[5 ] -= 1 Hash[10 ] = Hash.get(10 , 0 ) + 1 else : return False elif bill == 20 : if Hash.get(10 , 0 ) > 0 and Hash.get(5 , 0 ) > 0 : Hash[10 ] -= 1 Hash[5 ] -= 1 elif Hash.get(5 , 0 ) > 2 : Hash[5 ] -= 3 else : return False return True
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 给定一个数组,它的第 i 个元素是一支给定股票第 i 天的价格。设计一个算法来计算你所能获取的最大利润。你可以尽可能地完成更多的交易(多次买卖一支股票)。注意:你不能同时参与多笔交易(你必须在再次购买前出售掉之前的股票)。 示例 1: 输入: [7,1,5,3,6,4] 输出: 7 解释: 在第 2 天(股票价格 = 1)的时候买入,在第 3 天(股票价格 = 5)的时候卖出, 这笔交易所能获得利润 = 5-1 = 4 。随后,在第 4 天(股票价格 = 3)的时候买入,在第 5 天(股票价格 = 6)的时候卖出, 这笔交易所能获得利润 = 6-3 = 3 。 示例 2: 输入: [1,2,3,4,5] 输出: 4 解释: 在第 1 天(股票价格 = 1)的时候买入,在第 5 天 (股票价格 = 5)的时候卖出, 这笔交易所能获得利润 = 5-1 = 4 。注意你不能在第 1 天和第 2 天接连购买股票,之后再将它们卖出。因为这样属于同时参与了多笔交易,你必须在再次购买前出售掉之前的股票。 示例 3: 输入: [7,6,4,3,1] 输出: 0 解释: 在这种情况下, 没有交易完成, 所以最大利润为 0。
方法: 贪心。只要判断价格是涨的,那么就买入,如果是跌的,那么就不买卖。
1 2 3 4 5 6 7 8 class Solution : def maxProfit (self, prices: List[int]) -> int: profit = 0 for i in range(1 , len(prices)): tmp = prices[i] - prices[i - 1 ] if tmp > 0 : profit += tmp return profit
1 2 3 4 5 6 7 8 9 10 11 假设你是一位很棒的家长,想要给你的孩子们一些小饼干。但是,每个孩子最多只能给一块饼干。对每个孩子 i,都有一个胃口值 g[i],这是能让孩子们满足胃口的饼干的最小尺寸;并且每块饼干 j,都有一个尺寸 s[j] 。如果 s[j] >= g[i],我们可以将这个饼干 j 分配给孩子 i ,这个孩子会得到满足。你的目标是尽可能满足越多数量的孩子,并输出这个最大数值。 示例 1: 输入: g = [1,2,3], s = [1,1] 输出: 1 解释: 你有三个孩子和两块小饼干,3个孩子的胃口值分别是:1,2,3。虽然你有两块小饼干,由于他们的尺寸都是1,你只能让胃口值是1的孩子满足。所以你应该输出1。 示例 2: 输入: g = [1,2], s = [1,2,3] 输出: 2 解释: 你有两个孩子和三块小饼干,2个孩子的胃口值分别是1,2。你拥有的饼干数量和尺寸都足以让所有孩子满足。所以你应该输出2.
方法: 排序,然后利用贪心算法。对饼干进行遍历,如果饼干能满足小孩胃口,满足小孩的数量+1,直到饼干遍历完或者小孩都满足
1 2 3 4 5 6 7 8 9 10 11 12 class Solution : def findContentChildren (self, g: List[int], s: List[int]) -> int: g.sort() s.sort() n = 0 N = len(g) for biscuit in s: if n==N: return n if biscuit>= g[n]: n += 1 return n
排序 https://www.cnblogs.com/onepixel/p/7674659.html
冒泡排序 1 2 3 4 5 6 7 def st (data) : length = len(data) for x in range(length - 1 ): for y in range(length - 1 - x): if data[y] > data[y+1 ]: data[y], data[y + 1 ] = data[y + 1 ], data[y] print(data)
选择排序 首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。以此类推,直到所有元素均排序完毕。
1 2 3 4 5 6 7 8 9 10 11 def st (data) : length = len(data) for x in range(0 , length): tmp_min = x for y in range(x + 1 , length): if data[y] < data[tmp_min]: tmp_min = y data[x], data[tmp_min] = data[tmp_min], data[x] print(data)
插入排序
从第一个元素开始,该元素可以认为已经被排序;
取出下一个元素,在已经排序的元素序列中从后向前扫描;
如果该元素(已排序)大于新元素,将该元素移到下一位置;
重复步骤3,直到找到已排序的元素小于或者等于新元素的位置;
将新元素插入到该位置后;
重复步骤2~5
1 2 3 4 5 6 7 8 9 10 11 def st (arr) : for i in range(1 , len(arr)): key = arr[i] j = i - 1 while j >= 0 and key < arr[j]: arr[j + 1 ] = arr[j] j -= 1 arr[j + 1 ] = key print(arr)
快速排序(重点) https://blog.csdn.net/pengzonglu7292/article/details/84938910
从数列中挑出一个元素,称为 “基准”(pivot);
重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个分区退出之后,该基准就处于数列的中间位置。这个称为分区(partition)操作;
递归地(recursive)把小于基准值元素的子数列和大于基准值元素的子数列排序。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 def quick_sort (begin, end, nums) : if begin >= end: return pivot_index = partition(begin, end, nums) quick_sort(begin, pivot_index - 1 , nums) quick_sort(pivot_index + 1 , end, nums) def partition (begin, end, nums) : pivot = nums[begin] mark = begin for i in range(begin + 1 , end + 1 ): if nums[i] < pivot: mark += 1 nums[mark], nums[i] = nums[i], nums[mark] nums[begin], nums[mark] = nums[mark], nums[begin] return mark a = [10 , 4 , 23 , 9 , 6 , 10 , 22 , 1 , 4 , 99 , 890 , 8 ] quick_sort(0 , 11 , a) print(a)
归并排序(重点) https://www.cnblogs.com/chengxiao/p/6194356.html
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 def merge (a, b) : c = [] h = j = 0 while j < len(a) and h < len(b): if a[j] < b[h]: c.append(a[j]) j += 1 else : c.append(b[h]) h += 1 if j == len(a): for i in b[h:]: c.append(i) else : for i in a[j:]: c.append(i) return c def merge_sort (lists) : if len(lists) <= 1 : return lists middle = len(lists) // 2 left = merge_sort(lists[:middle]) right = merge_sort(lists[middle:]) return merge(left, right) if __name__ == '__main__' : a = [14 , 2 , 34 , 43 , 21 , 19 ] print(merge_sort(a))
堆排序 https://www.cnblogs.com/chengxiao/p/6129630.html
其他 https://github.com/HuberTRoy/leetCode
https://leetcode-cn.com/