以 kubeadm 安装的 k8s 集群,都会将 api server,etcd,controller-manager,scheduler,kubulet,kube-proxy 等以 Pod 的方式来启动。手工部署则是运行为系统级守护进程。
使用 kubeadm 安装 k8s 集群的步骤:
- master, nodes: 安装 kubelet, kubeadm, docker, kubectl
- master:kubeadm init
- nodes:kubeadm join
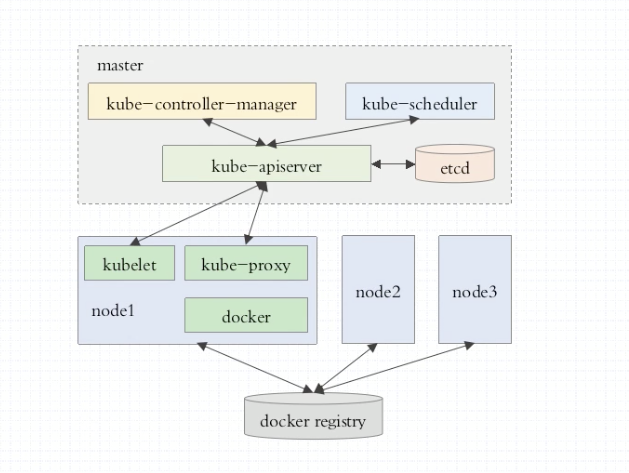
在阿里云上购买三台硅谷的抢占式 ECS 实例
Master
修改 SSH 断开时间
1 | echo export TMOUT=1000000 >> /root/.bash_profile |
安装Docker
1 | yum -y install docker |
1 | systemctl start docker.service |
安装kubeadm,kubelet和kubectl
kubeadm:引导群集的命令。kubelet:在群集中的所有计算机上运行的组件,并执行诸如启动pod和容器之类的操作。kubectl:用于与群集通信的命令行util。
1 | cat <<EOF > /etc/yum.repos.d/kubernetes.repo |
1 | Set SELinux in permissive mode (effectively disabling it) |
1 | yum install -y kubelet kubeadm kubectl --disableexcludes=kubernetes |
1 | systemctl enable --now kubelet |
初始化 Master
初始化需要指定 –pod-network-cidr,如果 Pod 网络插件采用 Flannel,那么 –pod-network-cidr 的值需要和 Flannel yml 配置文件中的一致。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69[root@iZrj9be8chbky2q6pegw28Z ~]# kubeadm init --apiserver-advertise-address 172.20.245.177 --pod-network-cidr 10.244.0.0/16 --ignore-preflight-errors=All
[init] Using Kubernetes version: v1.14.1
[preflight] Running pre-flight checks
[preflight] Pulling images required for setting up a Kubernetes cluster
[preflight] This might take a minute or two, depending on the speed of your internet connection
[preflight] You can also perform this action in beforehand using 'kubeadm config images pull'
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Activating the kubelet service
[certs] Using certificateDir folder "/etc/kubernetes/pki"
[certs] Generating "etcd/ca" certificate and key
[certs] Generating "etcd/peer" certificate and key
[certs] etcd/peer serving cert is signed for DNS names [izrj9be8chbky2q6pegw28z localhost] and IPs [172.20.245.177 127.0.0.1 ::1]
[certs] Generating "apiserver-etcd-client" certificate and key
[certs] Generating "etcd/server" certificate and key
[certs] etcd/server serving cert is signed for DNS names [izrj9be8chbky2q6pegw28z localhost] and IPs [172.20.245.177 127.0.0.1 ::1]
[certs] Generating "etcd/healthcheck-client" certificate and key
[certs] Generating "front-proxy-ca" certificate and key
[certs] Generating "front-proxy-client" certificate and key
[certs] Generating "ca" certificate and key
[certs] Generating "apiserver" certificate and key
[certs] apiserver serving cert is signed for DNS names [izrj9be8chbky2q6pegw28z kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local] and IPs [10.96.0.1 172.20.245.177]
[certs] Generating "apiserver-kubelet-client" certificate and key
[certs] Generating "sa" key and public key
[kubeconfig] Using kubeconfig folder "/etc/kubernetes"
[kubeconfig] Writing "admin.conf" kubeconfig file
[kubeconfig] Writing "kubelet.conf" kubeconfig file
[kubeconfig] Writing "controller-manager.conf" kubeconfig file
[kubeconfig] Writing "scheduler.conf" kubeconfig file
[control-plane] Using manifest folder "/etc/kubernetes/manifests"
[control-plane] Creating static Pod manifest for "kube-apiserver"
[control-plane] Creating static Pod manifest for "kube-controller-manager"
[control-plane] Creating static Pod manifest for "kube-scheduler"
[etcd] Creating static Pod manifest for local etcd in "/etc/kubernetes/manifests"
[wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory "/etc/kubernetes/manifests". This can take up to 4m0s
[apiclient] All control plane components are healthy after 15.502031 seconds
[upload-config] storing the configuration used in ConfigMap "kubeadm-config" in the "kube-system" Namespace
[kubelet] Creating a ConfigMap "kubelet-config-1.14" in namespace kube-system with the configuration for the kubelets in the cluster
[upload-certs] Skipping phase. Please see --experimental-upload-certs
[mark-control-plane] Marking the node izrj9be8chbky2q6pegw28z as control-plane by adding the label "node-role.kubernetes.io/master=''"
[mark-control-plane] Marking the node izrj9be8chbky2q6pegw28z as control-plane by adding the taints [node-role.kubernetes.io/master:NoSchedule]
[bootstrap-token] Using token: p8qz5z.ctkrg6zbclwmyja9
[bootstrap-token] Configuring bootstrap tokens, cluster-info ConfigMap, RBAC Roles
[bootstrap-token] configured RBAC rules to allow Node Bootstrap tokens to post CSRs in order for nodes to get long term certificate credentials
[bootstrap-token] configured RBAC rules to allow the csrapprover controller automatically approve CSRs from a Node Bootstrap Token
[bootstrap-token] configured RBAC rules to allow certificate rotation for all node client certificates in the cluster
[bootstrap-token] creating the "cluster-info" ConfigMap in the "kube-public" namespace
[addons] Applied essential addon: CoreDNS
[addons] Applied essential addon: kube-proxy
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 172.20.245.177:6443 --token p8qz5z.ctkrg6zbclwmyja9 \
--discovery-token-ca-cert-hash sha256:58613d36b9f6ad46f8455e134b626b52bd4992f65c6fbfeb97169905ac2ce92a
init 之后查看 docker 镜像,会发现 init 拉取了 kubeadm 所需的镜像。因为 kubeadm 会将 Api Server,etcd 等以 Pod 的方式启动(静态),所有会看到所需的镜像。

1 | mkdir -p $HOME/.kube |
获取组件状态信息
1 | kubectl get cs |

获取节点信息
kubectl get nodes 获取节点信息
查看 nodes 发现master NotReady,我们需要安装一下 flannel 网络插件
获取名称空间
kubectl get ns 获取所有的名称空间
查看指定名称空间
kubectl get pods -n kube-system 查看名称空间为 kube-system(系统级别,默认为 default) 的 pods
安装 Flannel
https://github.com/coreos/flannel1
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml

安装之后我们就能看到 Master 从 NotReady 变成了 Ready
Nodes
- 安装 Docker,启动服务
- 安装kubeadm,kubelet和kubectl
join。在 Node 上执行上面 init 之后得到的结果,让 Node 加入集群中

获取所有 nodes 信息

最后我们将本次实验的 master 中的 docker 镜像下载,这样就能在本地使用 kubeadm 进行安装了,而不必在国外机器进行实验。
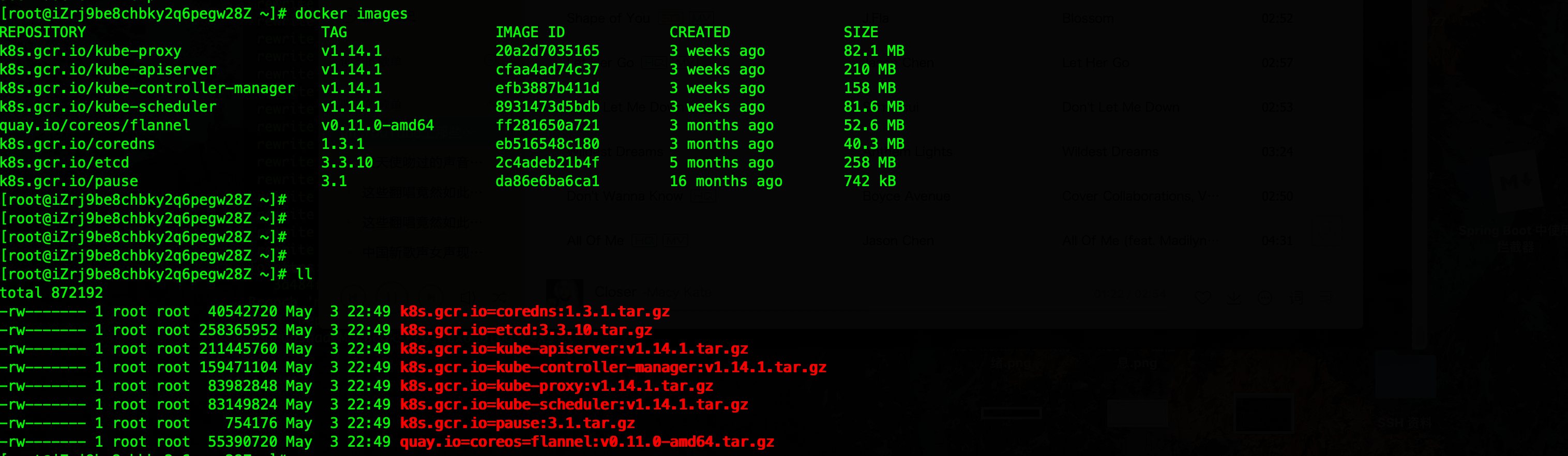
1 | docker save -o k8s.gcr.io=kube-proxy:v1.14.1.tar.gz k8s.gcr.io/kube-proxy:v1.14.1 |