Flask 源码分析
WSGI接口的作用是确保HTTP请求能够转化成python应用的一个功能调用,这也就是Gateway的意义所在,网关的作用就是在协议之前进行转换
https://blog.csdn.net/tianshuqitanyang/article/details/90082907
设计模式
简单工厂模式,我的理解是:某类产品的成产线。通过设置不同的参数,生产出同一类别下不同形态的产品。 举个例子: 手机生产线上,通过设置不同的参数既可以生成小米手机,也可以生成IPhone手机。
优点:工厂类是整个模式的关键.包含了必要的逻辑判断,根据外界给定的信息,决定究竟应该创建哪个具体类的对象.通过使用工厂类,外界可以从直接创建具体产品对象的尴尬局面摆脱出来,仅仅需要负责“消费”对象就可以了。而不必管这些对象究竟如何创建及如何组织的.明确了各自的职责和权利,有利于整个软件体系结构的优化。
缺点:由于工厂类集中了所有实例的创建逻辑,违反了高内聚责任分配原则,将全部创建逻辑集中到了一个工厂类中;它所能创建的类只能是事先考虑到的,如果需要添加新的类,则就需要改变工厂类了。当系统中的具体产品类不断增多时候,可能会出现要求工厂类根据不同条件创建不同实例的需求.这种对条件的判断和对具体产品类型的判断交错在一起,很难避免模块功能的蔓延,对系统的维护和扩展非常不利;
提供一个创建一系列相关或相互依赖对象的接口, 而无需指定他们具体的类
优点: 易于交换产品, 具体工厂配置不同的产品。让具体的创建实例过程与客户端分离, 客户端是通过它们的抽象接口操纵实例, 产品的具体类名也被具体工厂的实现分离, 不会出现在客户端的代码中。接口和实现分离,客户端面向接口编程,不用关心具体实现,从具体的产品实现中解耦
缺点:不易增加新的产品,如果要增加新的产品需要抽象工厂和所有具体工厂。
以游戏为例,定义一个抽象工厂,生产射击和塔防两种游戏,有两个具体的生产工厂,任天堂和腾讯,两个工厂生产各自品牌的两类游戏产品。
如果将抽象工厂模式看成汽车配件生产工厂,生产一个产品族的产品,那么建造者模式就是一个汽车组装工厂,通过对部件的组装可以返回一辆完整的汽车.
优点:使用建造者模式可以使客户端不必知道产品内部组成的细节。具体的建造者类之间是相互独立的,这有利于系统的扩展。具体的建造者相互独立,因此可以对建造的过程逐步细化,而不会对其他模块产生任何影响。
缺点:建造者模式所创建的产品一般具有较多的共同点,其组成部分相似;如果产品之间的差异性很大,则不适合使用建造者模式,因此其使用范围受到一定的限制。 如果产品的内部变化复杂,可能会导致需要定义很多具体建造者类来实现这种变化,导致系统变得很庞大。
单例
经常换手机的人可能会知道,手机的充电接口有几种,安卓的接口现在大多是Type-C了,一些低端机可能还在用Micro USB接口,而苹果则是用Lightining接口,假如我现在买了个新手机是Type-C接口,那我以前的那个Micro USB数据线还能不能继续用呢,是可以用的,只不过需要加上一个转接头,这个转接头便是一个适配器。
asyncio
https://zhuanlan.zhihu.com/p/59621713
消息队列
https://blog.csdn.net/qq_28900249/article/details/90346599
https://www.cnblogs.com/kx33389/p/11182082.html
AR(所有的副本) = ISR (与leader副本保持一定程度同步的副本) + OSR(与leader副本同步滞后过多的副本)
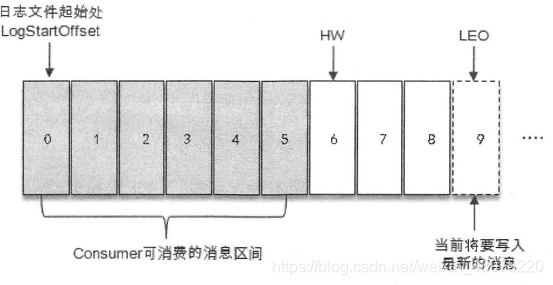
HW(高水位) 代表 HW 之前的消息是可以被消费者消费的,LEO 代表下一条待写入消息的 offset 位置。
MySQL
MyISAM 不支持事务,不支持外键,索引和数据文件分开,查询性能更好,适用于插入少,大量查询的场景。
聚簇索引 和 非聚簇索引 https://www.jianshu.com/p/fa8192853184
什么情况下需要建立索引(主键自动创建索引,频繁做为查询条件的字段,外键关联字段,排序字段等。经常增删改的表或者字段不适合,Where条件里用不到的字段不创建索引,过滤性不好的不适合建索引,例如,性别)
Explain 字段解释
索引使用的规则(单表查询,关联查询,order by查询,group by查询)
binlog 三种日志格式
MYSQL 主从
count(*) 和 count(字段) 的区别 https://juejin.im/post/6844903974445776903
事务隔离级别(读已提交,读未提交,可重复读,串行化 + 脏读,不可重复读,幻读) https://www.cnblogs.com/vinter/p/12581238.html
MVCC https://mp.weixin.qq.com/s/0-YEqTMd0OaIhW99WqavgQ
MYSQL 避免回表,索引覆盖 https://www.cnblogs.com/myseries/p/11265849.html
MYSQL 锁 https://blog.csdn.net/Saintyyu/article/details/91269087
MYSQL 分页优化:https://mp.weixin.qq.com/s/i6FL1iRECiWZ1CCf_juxQQ
Redis
和 memcached 的区别
key 过期策略,内存淘汰策略
主从复制/主从断点续传(谈一谈 offset 和 backlog,全量复制,增量复制)/主从key过期策略
主从心跳时间
redis 主从架构的高可用 - 主从 + 哨兵模式
故障转移哨兵集群至少需要几个节点
主从 + 哨兵模式怎么防止数据丢失(异步复制导致数据丢失,脑裂导致数据丢失)
redis 持久化(RDB,AOF 优缺点)
redis 集群
hash,一致性 hash,hash slot
redis 集群选举. https://baijiahao.baidu.com/s?id=1662783818493463629&wfr=spider&for=pc
缓存击穿,穿透,雪崩
缓存与数据库双写一致性
redis 并发竞争
redis 分布式锁的演进 https://blog.csdn.net/qq_40885085/article/details/106426172
redis redlock https://www.cnblogs.com/rgcLOVEyaya/p/RGC_LOVE_YAYA_1003days.html
https://www.cnblogs.com/kx33389/p/11298169.html
Celery 生产问题
僵尸进程,自动被杀死。设置 woker 并发数,每个 task 的执行时间
https://segmentfault.com/a/1190000019029934
1、当发起一个 task 时,会向 redis 的 celery key 中插入一条记录。
2、如果这时有正在待命的空闲 worker,这个 task 会立即被 worker 领取。
3、如果这时没有空闲的 worker,这个 task 的记录会保留在 celery key 中。
4、这时会将这个 task 的记录从 key celery 中移除,并添加相关信息到 unacked 和 unacked_index 中。
5、worker 根据 task 设定的期望执行时间执行任务,如果接到的不是延时任务或者已经超过了期望时间,则立刻执行。
6、worker 开始执行任务时,通知 redis。(如果设置了 CELERY_ACKS_LATE = True 那么会在任务执行结束时再通知)
7、redis 接到通知后,将 unacked 和 unacked_index 中相关记录移除。
8、如果在接到通知前,worker 中断了,这时 redis 中的 unacked 和 unacked_index 记录会重新回到 celery key 中。(这个回写的操作是由 worker 在 “临死” 前自己完成的,所以在关闭 worker 时为防止任务丢失,请务必使用正确的方法停止它,如: celery multi stop w1 -A proj1)
9、在 celery key 中的 task 可以再次重复上述 2 以下的流程。
10、celery 只是利用 redis 的 list 类型,当作个简单的 Queue,并没有使用消息订阅等功能
Flask
https://www.cnblogs.com/tianxiong/p/10739775.html
https://www.cnblogs.com/Infernal/p/11233850.html
WSGI接口的作用是确保HTTP请求能够转化成python应用的一个功能调用,这也就是Gateway的意义所在,网关的作用就是在协议之前进行转换。WSGI接口中有一个非常明确的标准,每个Python Web应用必须是可调用callable的对象且返回一个iterator,并实现了app(environ, start_response) 的接口,server 会调用 application,并传给它两个参数:environ 包含了请求的所有信息,start_response 是 application 处理完之后需要调用的函数,参数是状态码、响应头部还有错误信息。
werkzeug是基于python实现的WSGI的工具组件库,提供对HTTP请求和响应的支持,包括HTTP对象封装、缓存、cookie以及文件上传等等,并且werkzeug提供了强大的URL路由功能。具体应用到Flask中:
- Flask使用werkzeug库中的Request类和Response类来处理HTTP请求和响应
- Flask应用使用werkzeug库中的Map类和Rule类来处理URL的模式匹配,每一个URL模式对应一个Rule实例,这些Rule实例最终会作为参数传递给Map类构造包含所有URL模式的一个“地图”。
- Flask使用SharedDataMiddleware来对静态内容的访问支持,也即是static目录下的资源可以被外部
- Map,主要作用是提供ImmutableDict来存储URL的Rule实体。
- Rule,代表着URL与endpoint一对一匹配的模式规则
Flask 启动流程
werkzeug 的 run_simple 方法启动WSGI server并监听指定的端口ß
有请求时调用 run_wsgi,执行 app(environ, start_response)
执行 flask 的 __call__ 方法,并在里面调用 wsgi_app 方法
将请求推入栈中,执行 full_dispatch_request,通过路由寻找对应的处理函数进行处理
触发用户设置的在请求处理之前需要执行的函数,这个可以通过`@app.before_request`来设置
核心的处理函数,包括了路由的匹配,将 endpoint 与视图函数进行匹配。
元类编程
精通 HTTP / TCP 协议
tcp 三次握手 https://zhuanlan.zhihu.com/p/53374516
https://www.cnblogs.com/aidixie/p/11764181.html
https 验证证书阶段是非对称加密,传输数据是对称加密。https://blog.csdn.net/wuhuagu_wuhuaguo/article/details/78507762#2%E3%80%81HTTPS%E7%9A%84SSL%E8%BF%87%E7%A8%8B
http1.0:无连接,无状态,一次请求一个tcp连接。http1.1:持久连接,请求管道化(有一些缺陷) ,增加了host字段,缓存,断点续传。http2.0 : 二进制分帧(多路复用的实现基础), 多路复用,头部压缩
Django
https://blog.csdn.net/weixin_45476498/article/details/98883602
https://www.cnblogs.com/chongdongxiaoyu/p/9403399.html
大数据 Hadoop
Hbase
分布式 NoSQL 数据库
Hbase https://www.cnblogs.com/funyoung/p/10194432.html
Phoenix https://www.cnblogs.com/funyoung/p/10249115.html
ES
https://blog.csdn.net/abcd1101/article/details/89010070
https://www.cnblogs.com/heqiyoujing/p/11146178.html
https://zhuanlan.zhihu.com/p/102500311
排序算法
https://www.cnblogs.com/huang-yc/p/9774287.html
https://www.cnblogs.com/chenting123456789/p/11616656.html
二叉树遍历
https://www.cnblogs.com/lliuye/p/9143676.html
https://blog.csdn.net/wzngzaixiaomantou/article/details/81332293
https://www.cnblogs.com/anzhengyu/p/11083568.html
同步/异步/阻塞/非阻塞
阻塞和非阻塞,应该描述的是一种状态,同步与非同步描述的是行为方式
https://www.cnblogs.com/nufangrensheng/p/3588690.html
常见面试题
https://blog.csdn.net/y472360651/article/details/104786674
type object 之间的区别和联系,什么是元类
https://blog.csdn.net/u013205877/article/details/90727698
生成器和迭代器的区别
https://www.jianshu.com/p/dcc4c1af63c7
多个装饰器执行顺序
https://segmentfault.com/a/1190000016603109
类装饰器
https://www.jianshu.com/p/f758ef3b41d0
https://www.jianshu.com/p/99055ca39c2a
python 细节
https://www.jianshu.com/u/d891712a8350
Python字典dict实现原理
https://zhuanlan.zhihu.com/p/74003719
日志
https://www.jianshu.com/p/d615bf01e37b
Python 多进程和多线程
https://www.cnblogs.com/yssjun/p/11302500.html
Python 进程间通信的六种方式
https://github.com/chaseSpace/IPC-Inter-Process-Communication/blob/master/README.md
Python 线程之间的通信方式
https://www.cnblogs.com/shenh/p/10825656.html
协程
让原来要使用异步+回调方式写的非人类代码,可以用看似同步的方式写出来
select poll epoll 的区别
https://www.cnblogs.com/Anker/p/3265058.html
同步,异步
同步,异步强调的是消息通信机制
所谓同步,就是在发出一个”调用”时,在没有得到结果之前,该“调用”就不返回。但是一旦调用返回,就得到返回值了。换句话说,就是由“调用者”主动等待这个“调用”的结果。而异步则是相反
- 一个异步过程调用发出后,调用者不会立刻得到结果。而是在”调用”发出后,”被调用者”通过状态、通知来通知调用者,或通过回调函数处理这个调用
- 异步比如 ajax
阻塞,非阻塞
- 阻塞和非阻塞关注的是程序在等待调用结果(消息,返回值)时的状态.
同步就是烧开水,要自己来看开没开;异步就是水开了,然后水壶响了通知你水开了。阻塞是烧开水的过程中,你不能干其他事情(即你被阻塞住了);非阻塞是烧开水的过程里可以干其他事情。同步与异步说的是你获得水开了的方式不同。阻塞与非阻塞说的是你得到结果之前能不能干其他事情。两组概念描述的是不同的内容。
并行,并发
- 并发,指的是多个事情,在同一时间段内同时发生了。 并发的多个任务之间是互相抢占资源的。
- 并行,指的是多个事情,在同一时间点上同时发生了。并行的多个任务之间是不互相抢占资源的
- 只有在多CPU或者一个CPU多核的情况中,才会发生并行。否则,看似同时发生的事情,其实都是并发执行的。
其他题目
- 根据下标,删除另一个数组的元素
- 自己实现一个字典
- 最长回文子串
https://labuladong.gitbook.io/algo/di-ling-zhang-bi-du-xi-lie/qiang-fang-zi
https://greyireland.gitbook.io/algorithm-pattern/
Python 单例的三种写法
1 | from functools import wraps |
Python 常见面试题
https://github.com/JushuangQiao/Python-Offer
https://github.com/kenwoodjw/python_interview_question
https://github.com/python3xxx/Python-Every-Day
https://github.com/DasyDong/interview/blob/master/notes/python_interview.md