原理与实现
所谓“享元”,顾名思义就是被共享的单元。享元模式的意图是复用对象,节省内存,前提是享元对象是不可变对象。
具体来讲,当一个系统中存在大量重复对象的时候,如果这些重复的对象是不可变对象,我们就可以利用享元模式将对象设计成享元,在内存中只保留一份实例,供多处代码引用。这样可以减少内存中对象的数量,起到节省内存的目的。实际上,不仅仅相同对象可以设计成
享元,对于相似对象,我们也可以将这些对象中相同的部分(字段)提取出来,设计成享元,让这些大量相似对象引用这些享元。
定义中的“不可变对象”指的是,一旦通过构造函数初始化完成之后,它的状态(对象的成员变量或者属性)就不会再被修改了。所以,不可变对象不能暴露任何 set() 等修改内部状态的方法。之所以要求享元是不可变对象,那是因为它会被多处代码共享使用,避免一处代码对享元进行了修改,影响到其他使用它的代码。
所谓“享元”,顾名思义就是被共享的单元。享元模式的意图是复用对象,节省内存,前提是享元对象是不可变对象。具体来讲,当一个系统中存在大量重复对象的时候,我们就可以利用享元模式,将对象设计成享元,在内存中只保留一份实例,供多处代码引用,这样可以
减少内存中对象的数量,以起到节省内存的目的。实际上,不仅仅相同对象可以设计成享元,对于相似对象,我们也可以将这些对象中相同的部分(字段),提取出来设计成享元,让这些大量相似对象引用这些享元。享元模式的代码实现非常简单,主要是通过工厂模式,在工厂类中,通过一个 Map 或者 List 来缓存已经创建好的享元对象,以达到复用的目的。
应用举例一
假设我们在开发一个棋牌游戏(比如象棋)。一个游戏厅中有成千上万个“房间”,每个房间对应一个棋局。棋局要保存每个棋子的数据,比如:棋子类型(将、相、士、炮等)、棋子颜色(红方、黑方)、棋子在棋局中的位置。利用这些数据,我们就能显示一个完整的棋
盘给玩家。具体的代码如下所示。其中,ChessPiece 类表示棋子,ChessBoard 类表示一个棋局,里面保存了象棋中 30 个棋子的信息。


为了记录每个房间当前的棋局情况,我们需要给每个房间都创建一个 ChessBoard 棋局对象。因为游戏大厅中有成千上万的房间(实际上,百万人同时在线的游戏大厅也有很多),那保存这么多棋局对象就会消耗大量的内存。有没有什么办法来节省内存呢?
这个时候,享元模式就可以派上用场了。像刚刚的实现方式,在内存中会有大量的相似对象。这些相似对象的 id、text、color 都是相同的,唯独 positionX、positionY 不同。实际上,我们可以将棋子的 id、text、color 属性拆分出来,设计成独立的类,并且作为享元
供多个棋盘复用。这样,棋盘只需要记录每个棋子的位置信息就可以了。具体的代码实现如下所示:


在上面的代码实现中,我们利用工厂类来缓存 ChessPieceUnit 信息(也就是 id、text、color)。通过工厂类获取到的 ChessPieceUnit 就是享元。所有的 ChessBoard 对象共享这 30 个 ChessPieceUnit 对象(因为象棋中只有 30 个棋子)。在使用享元模式之前,记录 1 万个棋局,我们要创建 30 万(30*1 万)个棋子的 ChessPieceUnit 对象。利用享元模式,我们只需要创建 30 个享元对象供所有棋局共享使用即可,大大节省了内存。
实际上,它的代码实现非常简单,主要是通过工厂模式,在工厂类中,通过一个 Map 来缓存已经创建过的享元对象,来达到复用的目的。
应用举例二
如何利用享元模式来优化文本编辑器的内存占用?
假设这个文本编辑器只实现了文字编辑功能,不包含图片、表格等复杂的编辑功能。对于简化之后的文本编辑器,我们要在内存中表示一个文本文件,只需要记录文字和格式两部分信息就可以了,其中,格式又包括文字的字体、大小、颜色等信息。
从理论上讲,我们可以给文本文件中的每个文字都设置不同的格式。为了实现如此灵活的格式设置,并且代码实现又不过于太复
杂,我们把每个文字都当作一个独立的对象来看待,并且在其中包含它的格式信息。具体的代码示例如下所示:
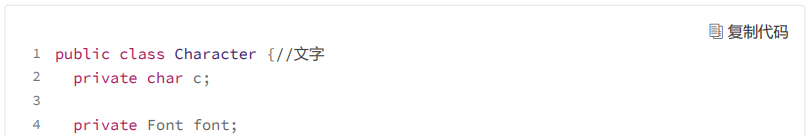
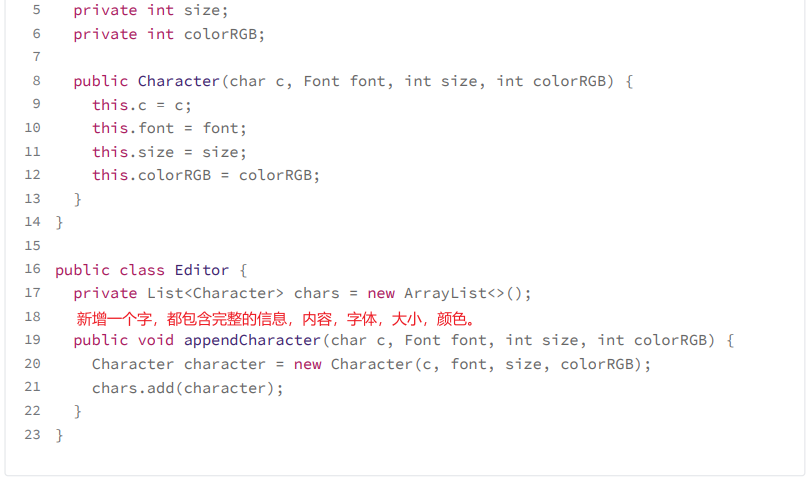
在文本编辑器中,我们每敲一个文字,都会调用 Editor 类中的 appendCharacter() 方法,创建一个新的 Character 对象,保存到 chars 数组中。如果一个文本文件中,有上万、十几万、几十万的文字,那我们就要在内存中存储这么多 Character 对象。那有没有办法可
以节省一点内存呢?
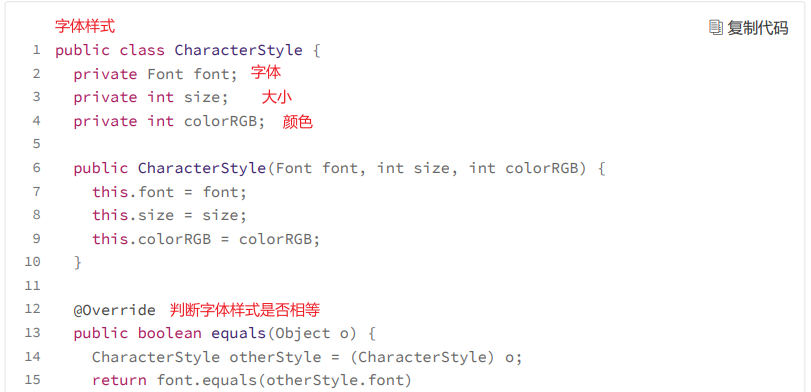
实际上,在一个文本文件中,用到的字体格式不会太多,毕竟不大可能有人把每个文字都设置成不同的格式。所以,对于字体格式,我们可以将它设计成享元,让不同的文字共享使用。按照这个设计思路,我们对上面的代码进行重构。重构后的代码如下所示:

和单例的区别
在单例模式中,一个类只能创建一个对象,而在享元模式中,一个类可以创建多个对象,每个对象被多处代码引用共享。实际上,享元模式有点类似于之前讲到的单例的变体:多例。尽管从代码实现上来看,享元模式和多例有很多相似之处,但从设计意图上来看,它们是完全不同的。应用享元模式是为了对象复用,节省内存,而应用多例模式是为了限制对象的个数。
和缓存的区别
在享元模式的实现中,我们通过工厂类来“缓存”已经创建好的对象。这里的“缓存”实际上是“存储”的意思,跟我们平时所说的“数据库缓存”“CPU 缓存”“MemCache 缓存”是两回事。我们平时所讲的缓存,主要是为了提高访问效率,而非复用。
和对象池的区别
池化技术中的“复用”可以理解为“重复使用”,主要目的是节省时间(比如从数据库池中取一个连接,不需要重新创建)。在任意时刻,每一个对象、连接、线程,并不会被多处使用,而是被一个使用者独占,当使用完成之后,放回到池中,再由其他使用者重复利用。享元模式中的“复用”可以理解为“共享使用”,在整个生命周期中,都是被所有使用者共享的,主要目的是节省空间。