目前市面上的数据库很多, 不同类型的数据库在不同的场景发挥着不同的作用,下面是一些数据库的简单分类:
| 类型 | 代表 | 场景 |
|---|---|---|
| 关系型数据库(RDBMS) | MySQL、PostgreSQL、MariaDB | 这些数据库对于结构化数据和复杂查询非常适用。如果你需要对文章进行复杂的关联查询或者需要强大的事务支持,关系型数据库是不错的选择。 |
| 文档数据库 | MongoDB、Couchbase | 这些数据库以文档的形式存储数据,适合存储非结构化的文档。如果你的文章包含各种不同类型的信息,文档数据库可能更适合。 |
| 图数据库 | Neo4j、ArangoDB | 如果你的系统需要处理大量复杂的关系网络,比如文章之间的引用、链接等,图数据库可能更适合。 |
| 全文搜索引擎 | Elasticsearch、Apache Solr | 这些工具专注于文本搜索和分析。如果你需要快速、强大的全文搜索功能,可以考虑集成这类搜索引擎。 |
| 分布式数据库 | Cassandra、HBase | 针对大规模数据存储和高可用性设计的分布式数据库。如果你需要处理大量文章并且需要水平扩展,考虑这类数据库。 |
MongoDB
功能定位
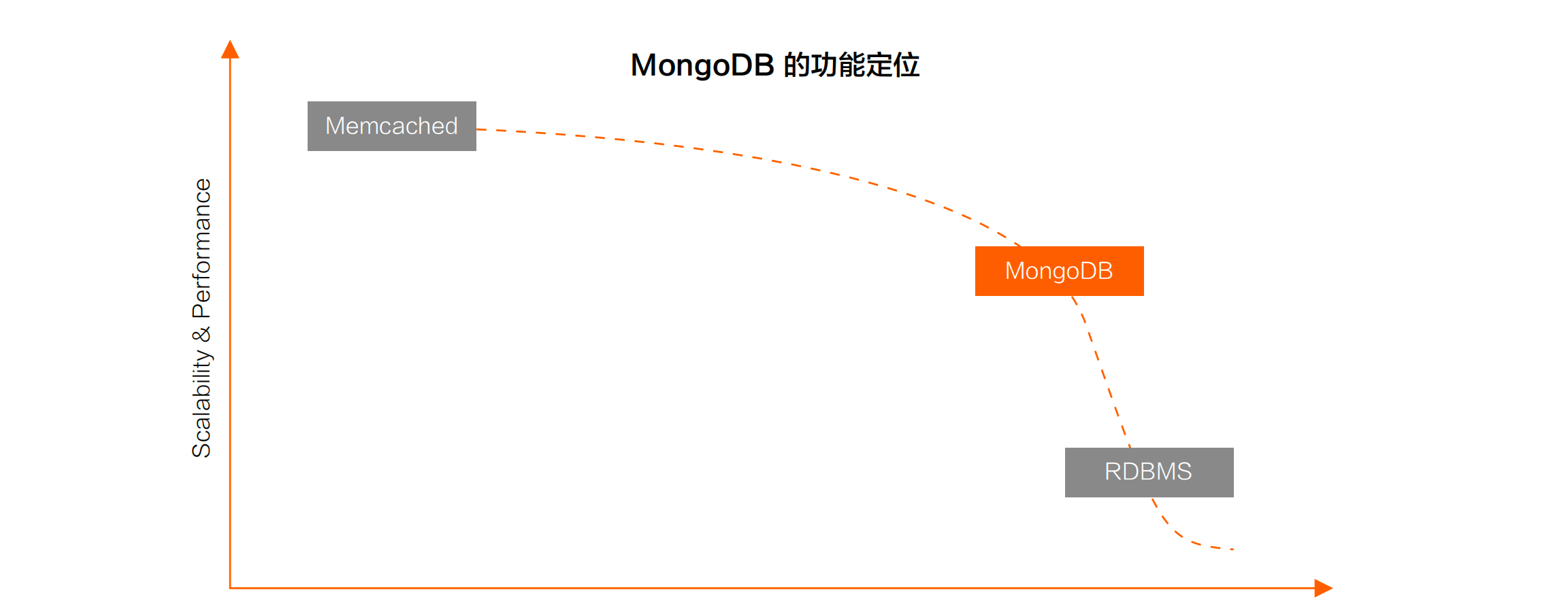
定位上,MongoDB 介于 Memcached 和关系型数据库之间,扩展性和性能上,MongoDB 更接近于Memcached,功能上,MongoDB 更接近于关系型数据库。
部署模型

在生产环境中,MongoDB 经常会部署成一个三节点的复制集,或者一个分片集群。我们先来看左边。当 MongoDB 部署为一个复制集时,应用程序通过驱动,直接请求复制集中的主节点,完成读写操作。另外两个从节点,会自动和主节点同步,保持数据的更新。在集群运行的过程中,万一主节点遇到故障,两个从节点会在几秒的时间内选举出新的主节点,继续支持应用的读写操作。我们再来看右边,当 MongoDB 被部署为一个分片集群时,应用程序通过驱动,访问路由节点,也就是 Mongos 节点 Mongos 节点会根据读写操作中的片键值,把读写操作分发的特定的分片执行,然后把分片的执行结果合并,返回给应用程序。那集群中的数据是如何分布的呢?这些元数据记录在 Config Server 中,这也是一个高可用的复制集。每个分片管理集群中整体数据的一部分,也是一个高可用复制集。此外,路由节点,也就是 Mongos 节点在生产环境通常部署多个。这样,整个分片集群没有任何单点故障。
与关系型数据库对应
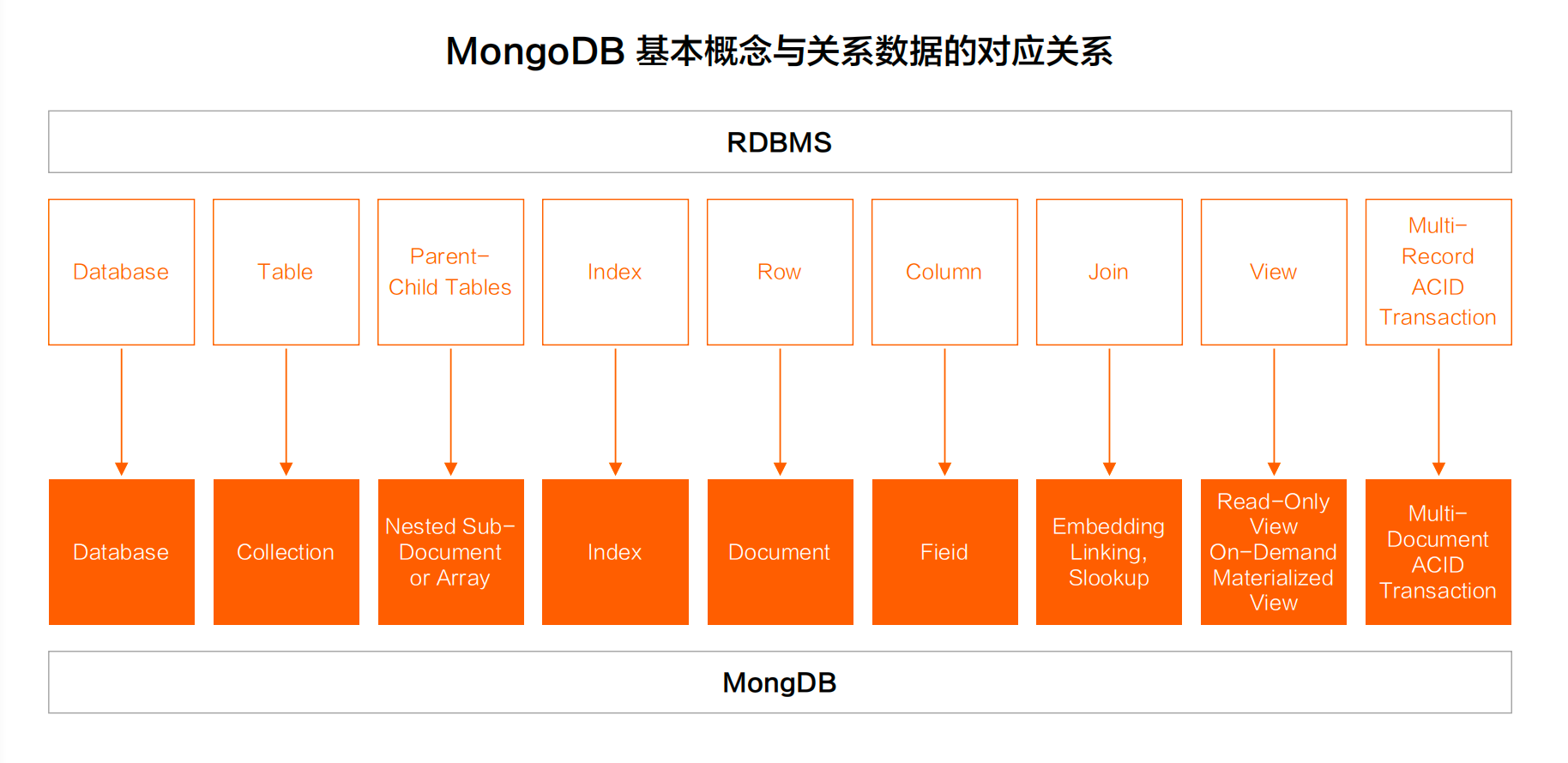
只有左外连接
只有左外连接?
- MongoDB 里面连接 Join 操作只有左外连接,因为 Join 这种操作上是违反 MongoDB设计的初衷的,这样操作经常要对两个表的不同数据进行连接操作,这些数据在物理存储的时候,通常不是在相邻的区域里面,读取效率比较低。
- MongoDB 是一个分布式的环境,校验操作的左右两边如果都是一个分片的表,当进行 Join 操作的时候,左边有一个又有一条数据,它可能在分片一上要连接的一个数据可能在分片二上,下一条数据可能又是另外一种情况,这种情况下数据库很难保证整个操作的性能。
- 基于这些原因,MongoDB 只提供左外连接,并且要求 From 表不能是分片表,左边的表主表可以是分片表。
MongoDB 是 OLTP 型的数据库,跟 Oracle、MySQL、SQL Server 等 OLTP 型数据库对标。MySQL 能做的事情,MongoDB 都可以做,只不过做法不一样。从 MongoDB 4.0 开始完全支持跟交易相关的强事务。
优点
MongoDB 的三个优点:
第一,横向扩展能力,数据量或并发量增加时候架构可以自动扩展。MongoDB 是原生的分布式数据库,通过分片技术,可以做到 TB 甚至 PB 级的数据量,以及数千数万数十万到百万级的并发,或者是连接数等等。MySQL 就需要一些特定的分库分表,或者第三方的解决方案。
第二,灵活模型,适合迭代开发,数据模型多变场景。现在的开发都是讲究快速迭代,往往在第一个版本出来的时候,需求是不完整的,这个时候有一个比较灵活的、不固定结构的数据库,在开发时间上会节省非常多。
第三,JSON 数据结构,适合微服务/REST API。REST API 的后面其实都是我们现在用的都是一种 REST 或者 JSON 的数据结构,而 MongoDB 是一种非常原生的支持。
技术考量
基于技术需求选择 MongoDB
第一个指标:数据量。假设单表里面要保存的处理数据超过亿或者 10 亿的级别,而且使用挺频繁,这个时候就可以考虑使用 MongoDB。这种场景下如果用 MySQL 做分库分表,效率、稳定性、可靠性肯定没法跟 MongoDB 相比。
第二个指标,数据结构模型不确定,或者明确会多变。比如迭代开发的场景下,MongoDB 允许过程中快速迭代,不需要去修改它的 Schema,继续可以支持你的业务。
第三个指标,高并发读写,MongoDB 通过分片直接支持。比如线上应用,网上可能是有很大很多的用户一起使用,并发性会非常高,这个时候考虑到 MongoDB 的分布式分片集群,可以支撑非常大的并发。基于单机的,比如说 Oracle、MySQL、SQL Server 可能都会有很大的瓶颈。其他还有一些场景可以选择 MongoDB,如跨地区集群、地理位置查询、轻松支持异构数据与大宽表做海量数据的分析, MongoDB 都是非常明显的优势。
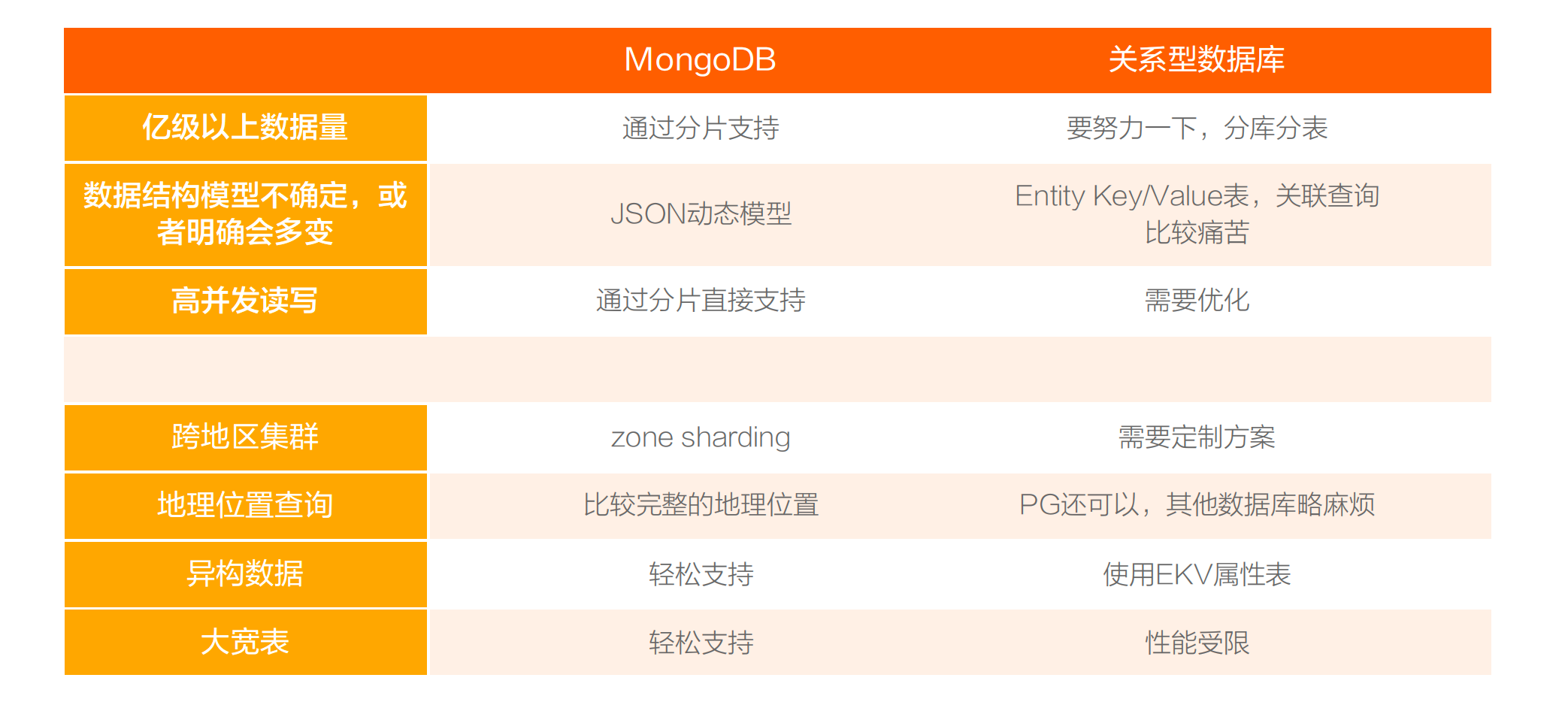
传统数据库只能做结构化数据。当有文本、PDF、音频、视频需要统一管理,关系数据库就吃力了。MongoDB 的 JSON 可以支持各种结构的数据,甚至二进制的数据,文本、日志更不在话下,它的分片结构可以支撑海量数据。所以 Gartner 魔力象限里面最顶上的两位,Adobe AEM 和 Sitecore 两个 CMS 文档管理系统的软件,都是用的 MongoDB 来做数据管理和存储。
MongoDB 什么时候不太适用?
MongoDB 模型设计不建议太多分表设计,关联能力较弱。
传统数据仓库:建立各种维度表,然后使用大量关联进行分析。
大型 ERP 软件,一级数据对象数量较多(超过数十数百),必须依赖于各种关联。
数据结构模型非常成熟固定,并且数据量不大,如财务系统。MongoDB 的弹性模型和分布式没有意义。
团队没有 MongoDB 能力,也没有时间让工程师学习新技术。
CouchDB
介绍及对比
它通过 MVCC 实现使用ACID模型而不是 BASE。就像MongoDB支持设备离线时的复制一样。它使用一种称为最终一致性的特殊复制模型
| 特性 | CouchDB | MongoDB |
|---|---|---|
| 数据模型 | 它遵循面向文档的模型,数据以JSON格式表示。 | 它遵循面向文档的模型,但数据以BSON格式表示 |
| 接口 | CouchDB使用基于HTTP/ REST的接口。它非常直观,设计非常好。 | MongoDB在TCP/IP上使用二进制协议和自定义协议。 |
| 对象存储 | 在CouchDB中,数据库包含文档。 | 在MongoDB中,数据库包含集合,而集合包含文档。 |
| 速度 | 它的读取速度是关键的数据库,MongoDB比CouchDB快 | MongoDB提供了更快的读取速度。 |
| 手机支持 | CouchDB可以运行在苹果iOS和Android设备上,为移动设备提供支持。 | 没有提供移动支援 |
| 大小 | 数据库可以随着CouchDB而增长;当结构从一开始就没有明确定义时,MongoDB更适合快速增长。 | 如果我们有一个快速增长的数据库,MongoDB是更好的选择。 |
| 查询方法 | 查询使用map-reduce函数。虽然它可能是一种优雅的解决方案,但对于具有传统SQL经验的人来说,学习它可能更加困难。 | MongoDB采用Map/Reduce (JavaScript)创建基于集合+对象的查询语言。对于有SQL知识的用户,MongoDB更容易学习,因为它更接近语法。 |
| 复制 | CouchDB支持使用自定义冲突解决功能的主-主复制。 | MongoDB支持主从复制。 |
| 并发性 | 它遵循MVCC(多版本并发控制)。 | 就地更新。 |
| 首选项 | CouchDB支持可用性。 | MongoDB支持一致性 |
| 性能的一致性 | CouchDB比MongoDB更安全 | |
| 一致性 | CouchDB最终是一致的。 | MongoDB是强一致性的。 |
| 编写语言 | Erlang | C++. |
| 分析 | 如果我们需要一个在移动设备上运行的数据库,需要主-主复制或单服务器持久性,那么CouchDB是一个很好的选择。 | 如果我们正在寻找最大的吞吐量,或者有一个快速增长的数据库,MongoDB是最好的选择。 |
Elasticsearch
结构化/非结构化/半结构化
数据主要分为两种:结构化数据和非结构化数据。这两类数据之间的根本区别在于数据的存储和分析方式。结构化数据遵循预定义的模式/模型,而非结构化数据则是自由形式、无组织的,没有模式。
结构化数据非常有组织,具有确定的形状和格式,并符合预定义的数据类型模式。它遵循定义好的模式,并且很容易搜索,因为它组织得很好。数据库中的数据被认为是结构化数据,因为在存储到数据库之前,它应该遵循严格的模式。例如,表示日期、数字或布尔值的数据必须以特定格式存储。 对结构化数据的查询返回精确匹配的结果。也就是说,我们关心的是找到与搜索标准相匹配的文档——而不是它们匹配得有多好。— 要么有结果,要么没结果。
除了结构化和非结构化数据,还有另一种类别:半结构化数据。这种数据基本上介于结构化和非结构化数据之间。它只不过是一些元数据描述的非结构化数据。
相关性是指搜索引擎的结果与用户查询的匹配程度。它是一种机制,用于指示结果与原始查询的匹配程度。搜索引擎使用相关性算法来确定哪些文档与用户的查询密切相关(即,它们有多相关),并根据结果与查询的匹配程度为每个结果生成一个正数,称为相关性分数。
Elasticsearch 使用相似性算法为全文查询生成相关性得分。得分是附加在结果上的正浮点数,得分最高的文档表示与查询标准更相关。Elasticsearch 高效地处理结构化和非结构化数据。其关键功能之一是能够在同一个索引中索引和搜索结构化和非结构化数据
原理介绍
Elasticsearch 是一个强大且流行的开源分布式搜索和分析引擎。它构建在 Apache Lucene 库之上,可以对结构化和非结构化数据执行近实时搜索和分析。
Elasticsearch、Solr和OpenSearch 它们都构建在Apache Lucene之上。
Solr 和 Elasticsearch 都擅长全文搜索;然而,Elasticsearch 在分析方面可能更有优势。Solr 更适合在大数据生态系统中的静态数据集
虽然 Elasticsearch 非常适合文本搜索,但它也可以对结构化和非结构化数据进行复杂的分析。例如,我们可以使用 Elasticsearch 执行聚合,分析日志数据,并使用 Kibana 可视化数据。
倒排索引:在搜索引擎中,每个文档都有对应的文档 ID,文档内容可以表示为一系列关键词的集合,例如,某个文档经过分词,提取了 20 个关键词,而通过倒排索引,可以记录每个关键词在文档中出现的次数和出现位置。也就是说,倒排索引是 关键词到文档 ID 的映射,每个关键词都对应着一系列的文件,这些文件中都出现了该关键词。
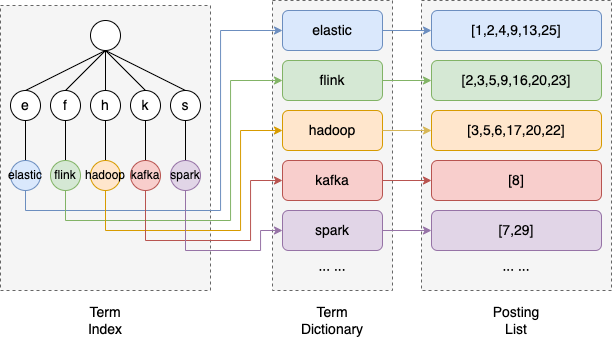
使用ES进行全文搜索时,系统首先会通过Term Index 找到该 Term 在 Term Dictionary 中的位置,再通过倒排索引结构找到对应的 Posting,从而定位到该词组在文本中的位置,完成一次搜索。
缺点及误解
缺点
Elasticsearch 不适合搜索具有关系且需要执行复杂数据库连接查询的场景
不适合需要立即一致性的应用,如金融交易
不是大规模地理空间分析的最有效解决方案。对于这些用例,可以考虑使用专用的地理空间数据库(如 PostGIS)或地理空间分析平台(如 ArcGIS)。
它不是针对高写入工作负载进行优化的,如果有此类场景,可以考虑如 Apache Flume 或 Apache Kafka。
在线分析处理(OLAP)数据-如果您需要对大型数据集执行复杂的多维分析,传统的 OLAP 数据库(如 Microsoft Analysis Services 或 IBM Cognos)可能比Elasticsearch更适合。
不能索引和搜索大型二进制数据(如视频或图像)的最佳解决方案。对于这些用例,请考虑使用专用的二进制数据存储,如 Hadoop 分布式文件系统(HDFS)、Amazon S3 或 Azure Files。
不能实时数据处理和分析的最有效的解决方案。相反,考虑一个专门的实时分析平台,比如 Apache SPark 或ApacheFlink。
ES 在处理大量数据时仍然存在延迟问题。对于需要亚毫秒级响应时间的应用程序,像Apache Solr这样的专门搜索引擎或像Apache Cassandra这样的柱形数据库可能更适合。
如果需要存储和分析时间序列数据,InfluxDB或TimescaleDB等专门的时间序列数据库可能更适合。类似地,像Neo4j这样的图形数据库可以帮助您处理图形数据。
误解
虽然Elasticsearch的设置和使用相对简单,但随着数据的增长和用例的增加,其管理和扩展可能具有挑战性。虽然一切都开箱即用,使工程师的生活变得轻松,但将Elasticsearch引入生产环境需要付出努力。随着数据的增长,我们可能需要调整配置和微调内存,管理节点故障,甚至缩放集群以处理千兆字节的数据。
Elasticsearch不是一个关系数据库,不支持传统的关系数据库特性,如事务、交换键和复杂的连接操作。例如,我们不能在Elasticsearch中强制引用完整性或执行复杂的连接操作
名词含义
| Elasticsearch 名词 | 含义 |
|---|---|
| index 索引 | 索引类似于mysql 中的数据库,Elasticesearch 中的索引是存在数据的地方,包含了一堆有相似结构的文档数据。 |
| type 类型 | 类型是用来定义数据结构,可以认为是 mysql 中的一张表,type 是 index 中的一个逻辑数据分类 |
| document 文档 | 类似于 MySQL 中的一行,不同之处在于 ES 中的每个文档可以有不同的字段,但是对于通用字段应该具有相同的数据类型,文档是es中的最小数据单元,可以认为一个文档就是一条记录。 |
| Field 字段 | Field是Elasticsearch的最小单位,一个document里面有多个field |
| shard 分片 | 单台机器无法存储大量数据,es可以将一个索引中的数据切分为多个shard,分布在多台服务器上存储。有了shard就可以横向扩展,存储更多数据,让搜索和分析等操作分布到多台服务器上去执行,提升吞吐量和性能。 |
| replica 副本 | 任何服务器随时可能故障或宕机,此时 shard 可能会丢失,通过创建 replica 副本,可以在 shard 故障时提供备用服务,保证数据不丢失,另外 replica 还可以提升搜索操作的吞吐量。 |
shard 分片数量在建立索引时设置;replica 副本数量默认1个,可随时修改数量;
写入流程
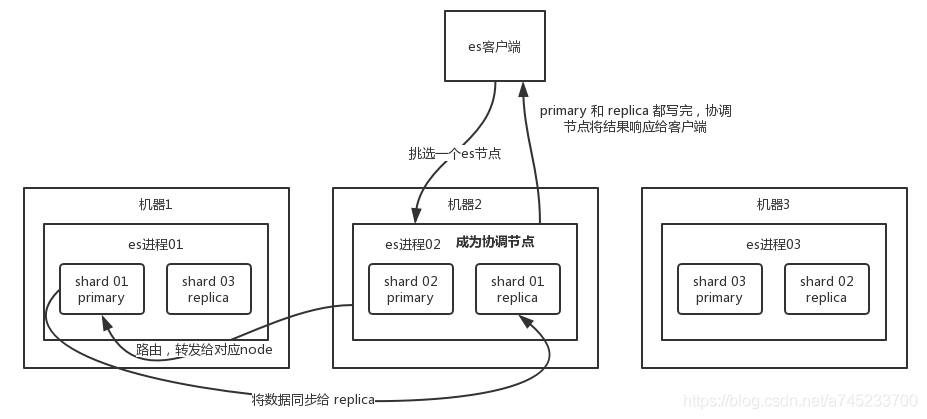
1、客户端选择 ES 的某个 node 发送请求过去,这个 node 就是协调节点 coordinating node
2、coordinating node 对 document 进行路由,将请求转发给对应的 node(有 primary shard)
3、实际的 node 上的 primary shard 处理请求,然后将数据同步到 replica node
4、coordinating node 等到 primary node 和所有 replica node 都执行成功之后,最后返回响应结果给客户端。
1、主分片先将数据写入ES的 memory buffer,然后定时(默认1s)将 memory buffer 中的数据写入一个新的 segment 文件中,并进入操作系统缓存 Filesystem cache(同时清空 memory buffer),这个过程就叫做 refresh;每个 segment 文件实际上是一些倒排索引的集合, 只有经历了 refresh 操作之后,这些数据才能变成可检索的。
ES 的近实时性:数据存在 memory buffer 时是搜索不到的,只有数据被 refresh 到 Filesystem cache 之后才能被搜索到,而 refresh 是每秒一次, 所以称 es 是近实时的;可以手动调用 es 的 api 触发一次 refresh 操作,让数据马上可以被搜索到;
2、由于 memory Buffer 和 Filesystem Cache 都是基于内存,假设服务器宕机,那么数据就会丢失,所以 ES 通过 translog 日志文件来保证数据的可靠性,在数据写入 memory buffer 的同时,将数据也写入 translog 日志文件中,当机器宕机重启时,es 会自动读取 translog 日志文件中的数据,恢复到 memory buffer 和 Filesystem cache 中去。
ES 数据丢失的问题:translog 也是先写入 Filesystem cache,然后默认每隔 5 秒刷一次到磁盘中,所以默认情况下,可能有 5 秒的数据会仅仅停留在 memory buffer 或者 translog 文件的 Filesystem cache中,而不在磁盘上,如果此时机器宕机,会丢失 5 秒钟的数据。也可以将 translog 设置成每次写操作必须是直接 fsync 到磁盘,但是性能会差很多。
这里复习一下 Redis AOF 三种写回策略:
- Always,同步写回:每个写命令执行完,立马同步地将日志写回磁盘;
- Everysec,每秒写回:每个写命令执行完,只是先把日志写到 AOF 文件的内存缓冲区,每隔一秒把缓冲区中的内容写入磁盘;
- No,操作系统控制的写回:每个写命令执行完,只是先把日志写到 AOF 文件的内存缓冲区,由操作系统决定何时将缓冲区内容写回磁盘。
三种策略的写回时机和优缺点:

3、flush 操作:不断重复上面的步骤,translog 会变得越来越大,不过 translog 文件默认每30分钟或者 阈值超过 512M 时,就会触发 commit 操作,即 flush操作,将 memory buffer 中所有的数据写入新的 segment 文件中, 并将内存中所有的 segment 文件全部落盘,最后清空 translog 事务日志。
- 将 memory buffer 中的数据 refresh 到 Filesystem Cache 中去,清空 buffer;
- 创建一个新的 commit point(提交点),同时强行将 Filesystem Cache 中目前所有的数据都 fsync 到磁盘文件中;
- 删除旧的 translog 日志文件并创建一个新的 translog 日志文件,此时 commit 操作完成
更新、删除流程
删除和更新都是写操作,但是由于 Elasticsearch 中的文档是不可变的,因此不能被删除或者改动以展示其变更;所以 ES 利用 .del 文件 标记文档是否被删除,磁盘上的每个段都有一个相应的.del 文件
- 如果是删除操作,文档其实并没有真的被删除,而是在 .del 文件中被标记为 deleted 状态。该文档依然能匹配查询,但是会在结果中被过滤掉。
- 如果是更新操作,就是将旧的 doc 标识为 deleted 状态,然后创建一个新的 doc。
- memory buffer 每 refresh 一次,就会产生一个 segment 文件 ,所以默认情况下是 1s 生成一个 segment 文件,这样下来 segment 文件会越来越多,此时会定期执行 merge。每次 merge 的时候,会将多个 segment 文件合并成一个,同时这里会将标识为 deleted 的 doc 给物理删除掉,不写入到新的 segment 中,然后将新的 segment 文件写入磁盘,这里会写一个 commit point ,标识所有新的 segment 文件,然后打开 segment 文件供搜索使用,同时删除旧的 segment 文件
搜索流程
Query阶段:客户端发送请求到 coordinate node,协调节点将搜索请求广播到所有的 primary shard 或 replica,每个分片在本地执行搜索并构建一个匹配文档的大小为 from + size 的优先队列。接着每个分片返回各自优先队列中 所有 docId 和 打分值 给协调节点,由协调节点进行数据的合并、排序、分页等操作,产出最终结果。
Fetch阶段:协调节点根据 Query阶段产生的结果,去各个节点上查询 docId 实际的 document 内容,最后由协调节点返回结果给客户端。
- coordinate node 对 doc id 进行哈希路由,将请求转发到对应的 node,此时会使用 round-robin 随机轮询算法,在 primary shard 以及其所有 replica 中随机选择一个,让读请求负载均衡。
- 接收请求的 node 返回 document 给 coordinate node 。
- coordinate node 返回 document 给客户端。
常见性能提升方法
Elasticsearch 的性能会不会很低:因为 ES只有建立 index 和 type 时需要经过 Master,而数据的写入有一个简单的 Routing 规则,可以路由到集群中的任意节点,所以数据写入压力是分散在整个集群的。
- 如果是大批量导入,可以设置 index.number_of_replicas: 0 关闭副本,等数据导入完成之后再开启副本
- 使用批量请求并调整其大小:每次批量数据 5–15 MB 大是个不错的起始点。
- 如果搜索结果不需要近实时性,可以把每个索引的 index.refresh_interval 改到30s
- 增加 index.translog.flush_threshold_size 设置,从默认的 512 MB 到更大一些的值,比如 1 GB
- 使用 SSD 存储介质
- 段和合并:Elasticsearch 默认值是 20 MB/s。但如果用的是 SSD,可以考虑提高到 100–200 MB/s。如果你在做批量导入,完全不在意搜索,你可以彻底关掉合并限流。
apache solr
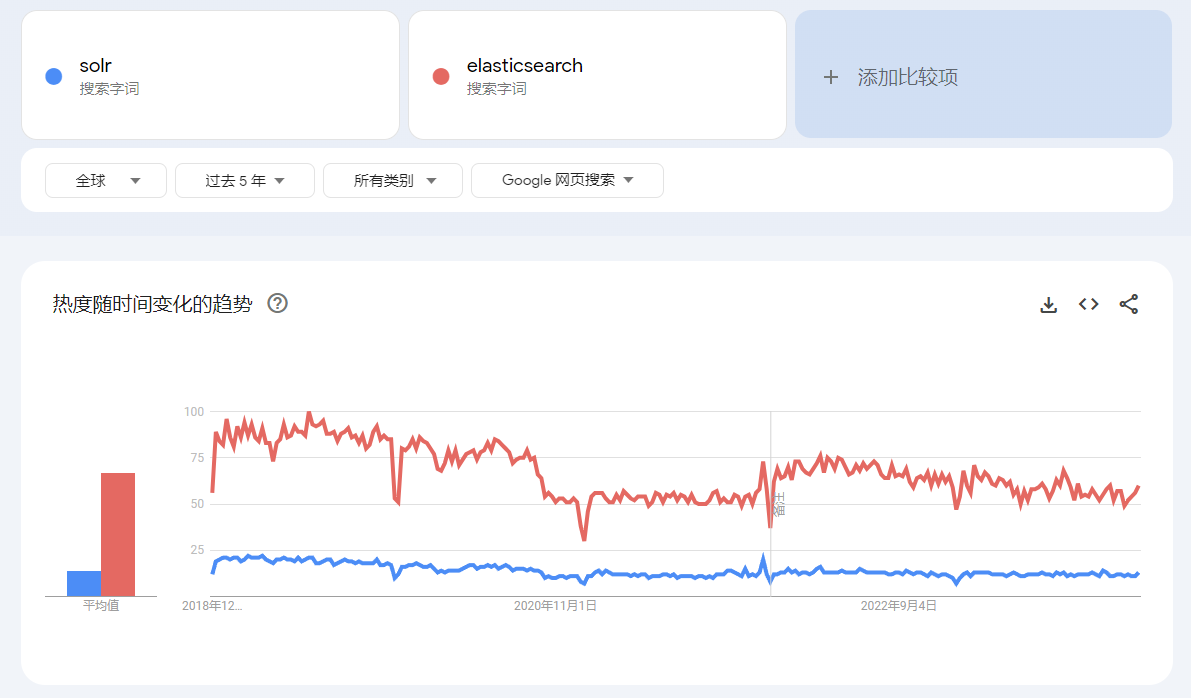
solr 和 es 过去五年在谷歌上的搜索对比
向量数据库
人类的文字、图片、视频等媒介是无法直接被计算机理解的,要想让计算机理解两段文字是否有相似性、相关性,通常需要将它们转成计算机可以理解的语言,向量是其中的一种方式。向量可以简单理解为一个数字数组,两个向量之间可以通过数学公式得出一个距离,距离越小代表两个向量的相似度越大。从而映射到文字、图片、视频等媒介上,可以用来判断两个媒介之间的相似度。向量搜索便是利用了这个原理。
而由于文字是有多种类型,并且拥有成千上万种组合方式,因此在转成向量进行相似度匹配时,很难保障其精确性。在向量方案构建的知识库中,通常使用topk召回的方式,也就是查找前k个最相似的内容,丢给大模型去做更进一步的语义判断、逻辑推理和归纳总结,从而实现知识库问答。因此,在知识库问答中,向量搜索的环节是最为重要的。
影响向量搜索精度的因素非常多,主要包括:向量模型的质量、数据的质量(长度,完整性,多样性)、检索器的精度(速度与精度之间的取舍)。与数据质量对应的就是检索词的质量。检索器的精度比较容易解决,向量模型的训练略复杂,因此数据和检索词质量优化成了一个重要的环节。
GPT 的缺陷
gpt-3.5-turbo 模型它的限制是 4K tokens(~3000字),这意味着使用者最多只能输入 3000 字给 GPT 来理解和推理答案。GPT 作为 LLM 模型是没有记忆功能的,所谓的记忆功能只是开发者将对话记录存储在内存或者数据库中,当你发送消息给 gpt 模型时,程序会自动将最近的几次对话记录(基于对话的字数限制在 4096 tokens 内)通过 prompt 组合成最终的问题,并发送给 ChatGPT。简而言之,如果你的对话记忆超过了 4096 tokens,那么它就会忘记之前的对话,这就是目前 GPT 在需求比较复杂的任务中无法克服的缺陷。
向量数据库解决的问题
在 GPT 模型的限制下,开发者们不得不寻找其他的解决方案,而向量数据库就是其中之一。向量数据库的核心思想是将文本转换成向量,然后将向量存储在数据库中,当用户输入问题时,将问题转换成向量,然后在数据库中搜索最相似的向量和上下文,最后将文本返回给用户。
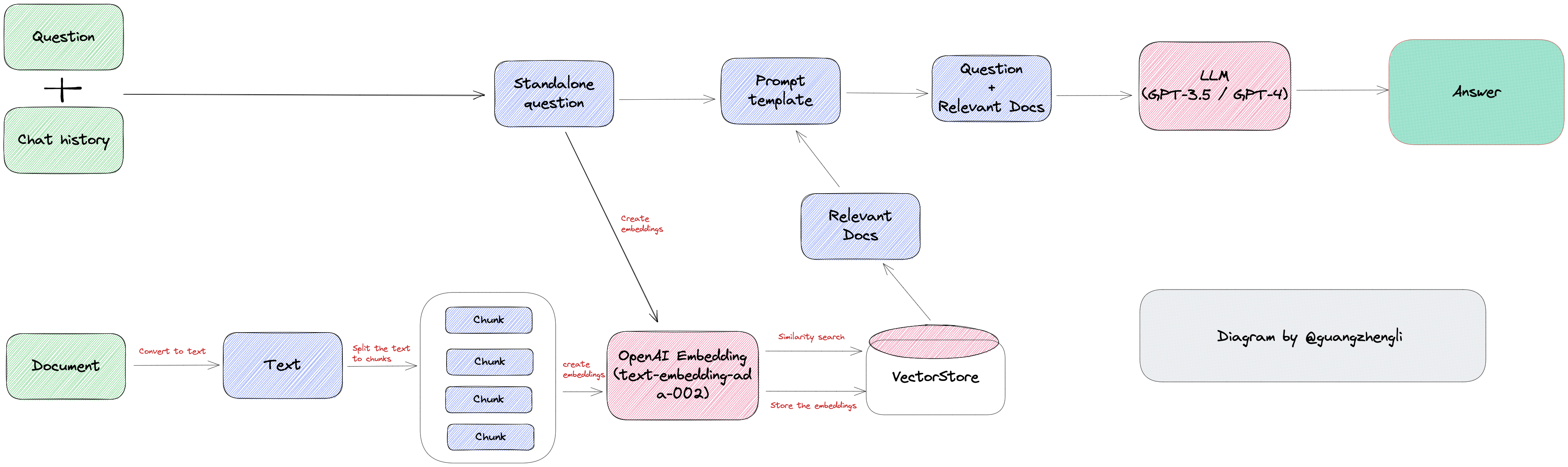
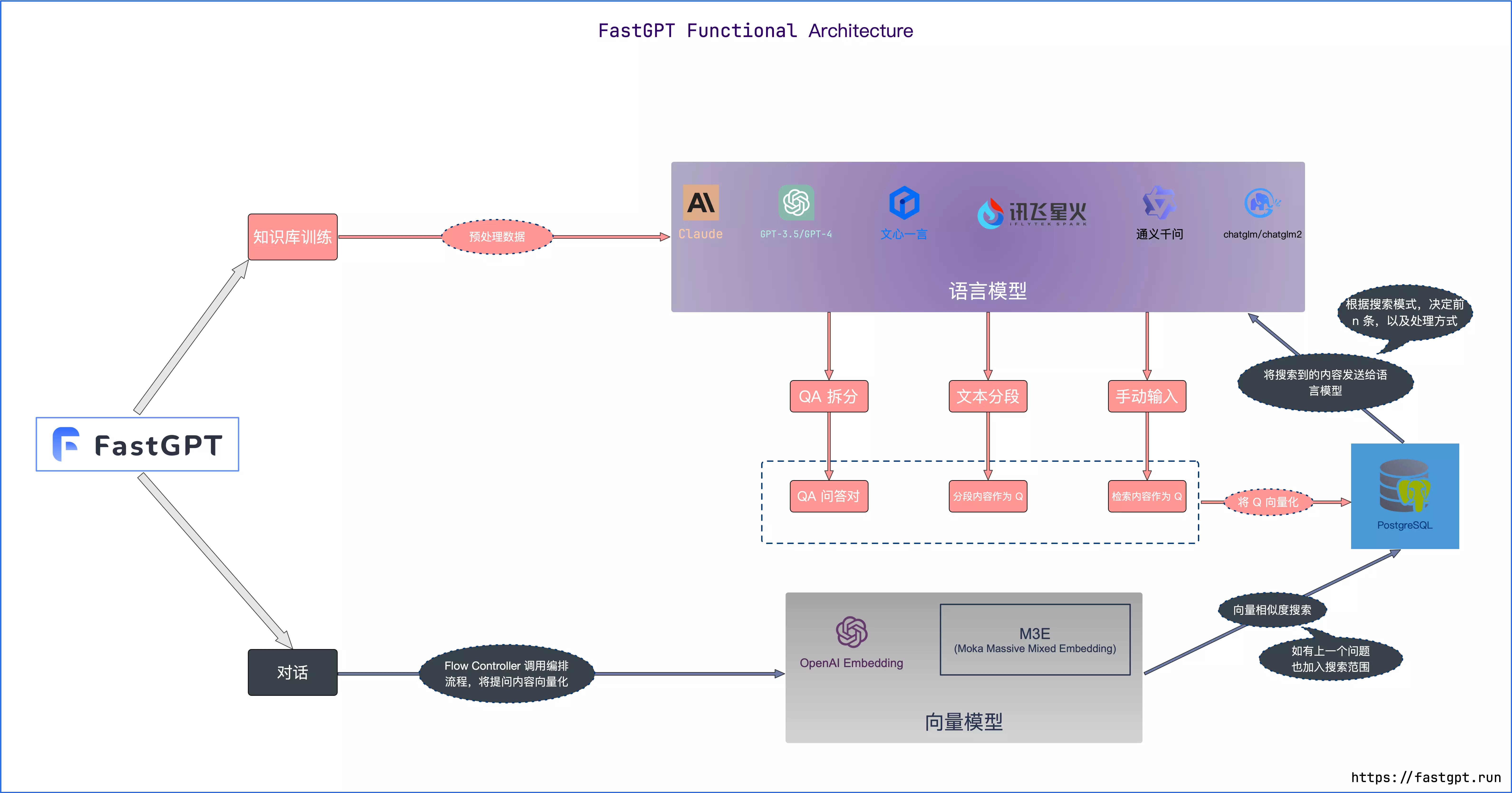
当我们有一份文档需要 GPT 处理时,例如这份文档是客服培训资料或者操作手册,我们可以先将这份文档的所有内容转化成向量(这个过程称之为 Vector Embedding),然后当用户提出相关问题时,我们将用户的搜索内容转换成向量,然后在数据库中搜索最相似的向量,匹配最相似的几个上下文,最后将上下文返回给 GPT。这样不仅可以大大减少 GPT 的计算量,从而提高响应速度,更重要的是降低成本,并绕过 GPT 的 tokens 限制。
向量数据库的作用当然不止步于文字语义搜索,在传统的 AI 和机器学习场景中,还包含人脸识别、图像搜索、语音识别等功能,但不可否认的是,这一轮向量数据库的火爆,正是因为它对于 AI 获得理解和维护长期记忆以执行复杂任务时有非常大的帮助。
Vector Embeddings
对于传统数据库,搜索功能都是基于不同的索引方式(B Tree、倒排索引等)加上精确匹配和排序算法(BM25、TF-IDF)等实现的。本质还是基于文本的精确匹配,这种索引和搜索算法对于关键字的搜索功能非常合适,但对于语义搜索功能就非常弱。
但是如果你需要处理非结构化的数据,就会发现非结构化数据的特征数量会开始快速膨胀,例如我们处理的是图像、音频、视频等数据,这个过程就变得非常困难。例如,对于图像,可以标注颜色、形状、纹理、边缘、对象、场景等特征,但是这些特征太多了,而且很难人为的进行标注,所以我们需要一种自动化的方式来提取这些特征,而这可以通过 Vector Embedding 实现。
Vector Embedding 是由 AI 模型(例如大型语言模型 LLM)生成的,它会根据不同的算法生成高维度的向量数据,代表着数据的不同特征,这些特征代表了数据的不同维度。例如,对于文本,这些特征可能包括词汇、语法、语义、情感、情绪、主题、上下文等。对于音频,这些特征可能包括音调、节奏、音高、音色、音量、语音、音乐等。
例如对于目前来说,文本向量可以通过 OpenAI 的 text-embedding-ada-002 模型生成,图像向量可以通过 clip-vit-base-patch32 模型生成,而音频向量可以通过 wav2vec2-base-960h 模型生成。这些向量都是通过 AI 模型生成的,所以它们都是具有语义信息的。
例如我们将这句话 “Your text string goes here” 用 text-embedding-ada-002 模型进行文本 Embedding,它会生成一个 1536 维的向量,得到的结果是这样:“-0.006929283495992422, -0.005336422007530928, ... -4547132266452536e-05,-0.024047505110502243”,它是一个长度为 1536 的数组。这个向量就包含了这句话的所有特征,这些特征包括词汇、语法,我们可以将它存入向量数据库中,以便我们后续进行语义搜索。
特征和向量
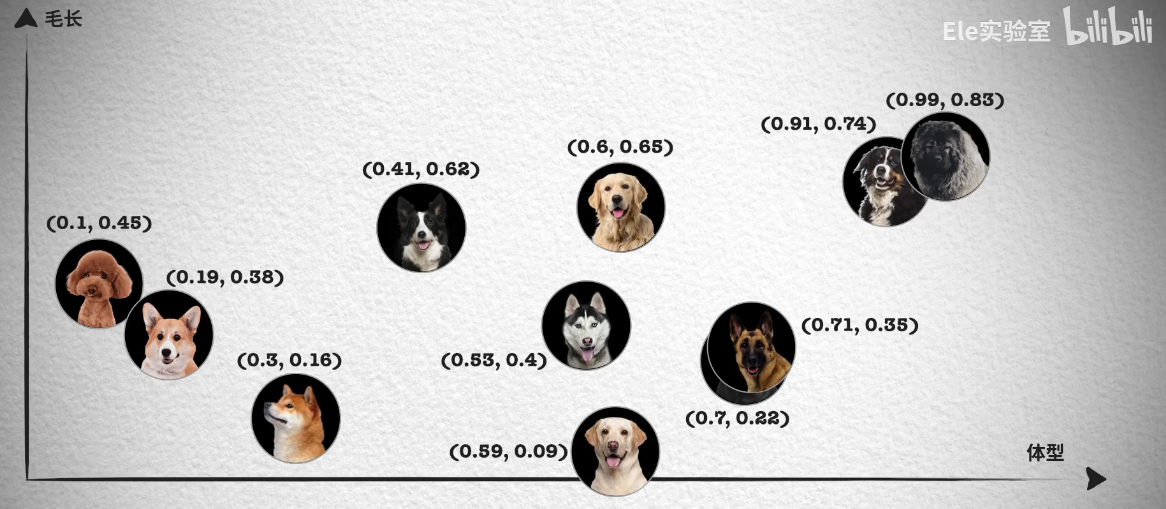
分别不同种类的小狗,就可以通过体型大小、毛发长度、鼻子长短等特征来区分。如下面这张照片按照体型排序,可以看到体型越大的狗越靠近坐标轴右边,这样就能得到一个体型特征的一维坐标和对应的数值,从 0 到 1 的数字中得到每只狗在坐标系中的位置。

然而单靠一个体型大小的特征并不够,像照片中哈士奇、金毛和拉布拉多的体型就非常接近,我们无法区分。所以我们会继续观察其它的特征,例如毛发的长短。
向量数据库选型
分布式
一个成熟的向量数据库,往往需要支持分布式部署,这样才能满足大规模数据的存储和查询。数据拥有的越多,需要节点就越多,出现的错误和故障也就越多,所以分布式的向量数据库需要具备高可用性和容错性。
数据库的高可用性和容错性,往往需要实现分片和复制能力,在传统的数据库中,往往通过数据的主键或者根据业务需求进行分片,但是在分布式的向量数据库中,就需要考虑根据向量的相似性进行分区,以便查询的时候能够保证结果的质量和速度。
其它类似复制节点数据的一致性、数据的安全性等等,都是分布式向量数据库需要考虑的因素。
访问控制和备份
除此之外,访问控制设计的是否充足,例如当组织和业务快速发展时,是否能够快速的添加新的用户和权限控制,是否能够快速的添加新的节点,审计日志是否完善等等,都是需要考虑的因素。
另外,数据库的监控和备份也是一个重要的因素,当数据出现故障时,能够快速的定位问题和恢复数据,是一个成熟的向量数据库必须要考虑的因素。
API & SDK
对比上面的因素选择,API & SDK 可能是往往被忽略的因素,但是在实际的业务场景中,API & SDK 往往是开发者最关心的因素。因为 API & SDK 的设计直接影响了开发者的开发效率和使用体验。一个优秀良好的 API & SDK 设计,往往能够适应需求的不同变化,向量数据库是一个新的领域,在如今大部分人不太清楚这方面需求的当下,这一点容易被人忽视。
| 向量数据库 | URL | GitHub Star | Language | Cloud |
|---|---|---|---|---|
| chroma | https://github.com/chroma-core/chroma | 9.9K | Python | ❌ |
| milvus | https://github.com/milvus-io/milvus | 24.5K | Go/Python/C++ | ✅ |
| pinecone | https://www.pinecone.io/ | ❌ | ❌ | ✅ |
| qdrant | https://github.com/qdrant/qdrant | 14.9K | Rust | ✅ |
| typesense | https://github.com/typesense/typesense | 16.2K | C++ | ❌ |
| weaviate | https://github.com/weaviate/weaviate | 8.4K | Go | ✅ |
| Vector Store | Type | Metadata Filtering | Hybrid Search | Delete | Store Documents | Async |
|---|---|---|---|---|---|---|
| Apache Cassandra® | self-hosted / cloud | ✓ | ✓ | ✓ | ||
| Astra DB | cloud | ✓ | ✓ | ✓ | ||
| Azure Cognitive Search | cloud | ✓ | ✓ | ✓ | ||
| Azure CosmosDB MongoDB | cloud | ✓ | ✓ | |||
| ChatGPT Retrieval Plugin | aggregator | ✓ | ✓ | |||
| Chroma | self-hosted | ✓ | ✓ | ✓ | ||
| DashVector | cloud | ✓ | ✓ | ✓ | ||
| Deeplake | self-hosted / cloud | ✓ | ✓ | ✓ | ||
| DocArray | aggregator | ✓ | ✓ | ✓ | ||
| DynamoDB | cloud | ✓ | ||||
| Elasticsearch | self-hosted / cloud | ✓ | ✓ | ✓ | ✓ | ✓ |
| FAISS | in-memory | |||||
| LanceDB | cloud | ✓ | ✓ | ✓ | ||
| Lantern | self-hosted / cloud | ✓ | ✓ | ✓ | ✓ | ✓ |
| Metal | cloud | ✓ | ✓ | ✓ | ||
| MongoDB Atlas | self-hosted / cloud | ✓ | ✓ | ✓ | ||
| MyScale | cloud | ✓ | ✓ | ✓ | ✓ | |
| Milvus / Zilliz | self-hosted / cloud | ✓ | ✓ | ✓ | ||
| Neo4jVector | self-hosted / cloud | ✓ | ✓ | |||
| OpenSearch | self-hosted / cloud | ✓ | ✓ | ✓ | ||
| Pinecone | cloud | ✓ | ✓ | ✓ | ✓ | |
| Postgres | self-hosted / cloud | ✓ | ✓ | ✓ | ✓ | ✓ |
| pgvecto.rs | self-hosted / cloud | ✓ | ✓ | ✓ | ✓ | |
| Qdrant | self-hosted / cloud | ✓ | ✓ | ✓ | ✓ | |
| Redis | self-hosted / cloud | ✓ | ✓ | ✓ | ||
| Simple | in-memory | ✓ | ✓ | |||
| SingleStore | self-hosted / cloud | ✓ | ✓ | ✓ | ||
| Supabase | self-hosted / cloud | ✓ | ✓ | ✓ | ||
| Tair | cloud | ✓ | ✓ | ✓ | ||
| TencentVectorDB | cloud | ✓ | ✓ | ✓ | ✓ | |
| Timescale | ✓ | ✓ | ✓ | ✓ | ||
| Typesense | self-hosted / cloud | ✓ | ✓ | ✓ | ||
| Weaviate | self-hosted / cloud | ✓ | ✓ | ✓ | ✓ |
国内有趣的开源产品都在用什么:
https://github.com/labring/FastGPT
https://github.com/guangzhengli/ChatFiles
https://github.com/GaiZhenbiao/ChuanhuChatGPT
技术架构
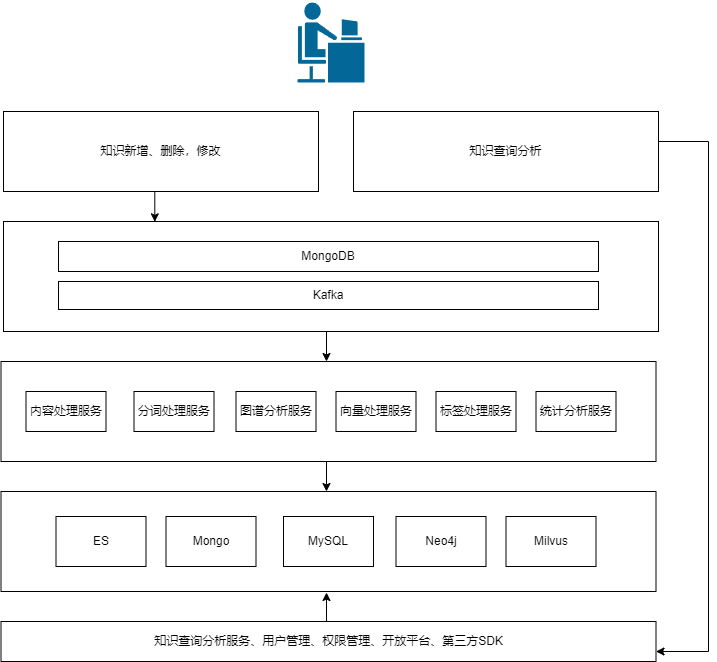
- 用户在前端页面进行文档的新增,删除,修改等操作。数据存储在 MongoDB (MySQL + Canal ?)中
- 数据通过消息队列流转到下游服务(文档内容处理,分词,图谱,向量,标签,统计…)进行处理
- 处理完后,将对应的数据存储到对应的数据库中,例如向量数据存储到向量数据库中,需要全文搜索的内容存储到 ES 中
- 用户在前端进行相对的搜索,分析等,查询对应数据服务中的数据
参考
https://guangzhengli.com/blog/zh/vector-database/
https://aws.amazon.com/cn/what-is/vector-databases/
《Elasticsearch in Action, Second Edition》
《玩转 MongoDB 从入门到实战》
《Redis 核心技术》