
判断子序列
给定字符串 s 和 t ,判断 s 是否为 t 的子序列。字符串的一个子序列是原始字符串删除一些(也可以不删除)字符而不改变剩余字符相对位置形成的新字符串。(例如,”ace”是”abcde”的一个子序列,而”aec”不是)。
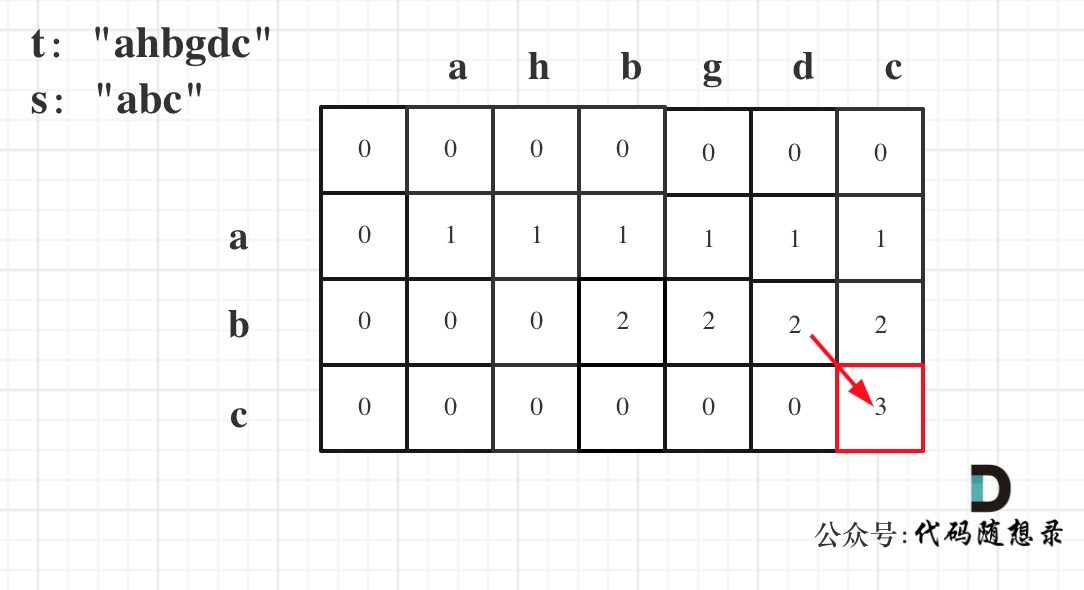
示例 1:输入:s = “abc”, t = “ahbgdc”,输出:true
示例 2:输入:s = “axc”, t = “ahbgdc”,输出:false
dp[i][j]表示以下标i-1为结尾的字符串s,和以下标j-1为结尾的字符串t,相同子序列的长度为dp[i][j]- 这里是判断s是否为t的子序列。即t的长度是大于等于s的
if (s[i - 1] == t[j - 1]),那么dp[i][j] = dp[i - 1][j - 1] + 1,因为找到了一个相同的字符,相同子序列长度自然要在dp[i-1][j-1]的基础上加1。if (s[i - 1] != t[j - 1]),此时相当于t要删除元素,t如果把当前元素t[j - 1]删除,那么dp[i][j]的数值就是 看s[i - 1]与 t[j - 2]的比较结果了,即:dp[i][j] = dp[i][j - 1]) 【注意理解 dp 数组的含义,这里其实相当于是 i-1 和 j-2,即在不相等的情况下,j元素后退了一个位置。】- 其实这里 大家可以发现和 1143.最长公共子序列的递推公式基本那就是一样的,区别就是 本题 如果删元素一定是字符串t,而 1143.最长公共子序列 是两个字符串都可以删元素。
dp[i][0]表示以下标i-1为结尾的字符串,与空字符串的相同子序列长度,所以为0。dp[0][j]同理也为0- 从递推公式可以看出
dp[i][j]都是依赖于dp[i - 1][j - 1]和dp[i][j - 1],那么遍历顺序也应该是从上到下,从左到右
以示例一为例,输入:s = “abc”, t = “ahbgdc”,dp状态转移图如下
1 | class Solution: |
不同的子序列
给定一个字符串 s 和一个字符串 t ,计算在 s 的子序列中 t 出现的个数。字符串的一个 子序列 是指,通过删除一些(也可以不删除)字符且不干扰剩余字符相对位置所组成的新字符串。(例如,”ACE” 是 “ABCDE” 的一个子序列,而 “AEC” 不是)

dp[i][j]:以i-1为结尾的s子序列中出现以 j-1为结尾的t的个数为dp[i][j]- 如果 s[i - 1] 与 t[j - 1]相等,
dp[i][j]可以有两部分组成- 一部分是用s[i - 1]来匹配,那么个数为
dp[i-1][j-1]。即不需要考虑当前s子串和t子串的最后一位字母,所以只需要dp[i-1][j-1]。 - 一部分是不用s[i - 1]来匹配,个数为
dp[i-1][j]。
- 一部分是用s[i - 1]来匹配,那么个数为
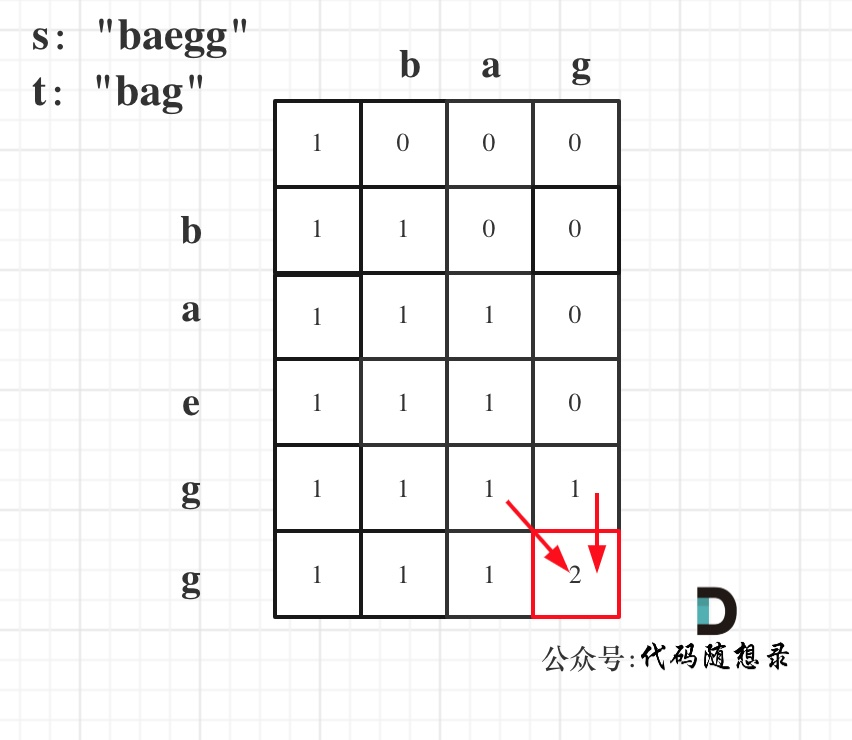
- s:bagg 和 t:bag ,s[3] 和 t[2]是相同的,但是字符串s也可以不用s[3]来匹配,即用s[0]s[1]s[2]组成的bag。当然也可以用s[3]来匹配,即:s[0]s[1]s[3]组成的bag。所以当s[i - 1] 与 t[j - 1]相等时,
dp[i][j] = dp[i-1][j-1] + dp[i-1][j] - 当s[i - 1] 与 t[j - 1]不相等时,
dp[i][j]只有一部分组成,不用s[i - 1]来匹配(就是模拟在s中删除这个元素),即:dp[i][j] = dp[i - 1][j] - 为什么只考虑 “不用s[i - 1]来匹配” 这种情况, 不考虑 “不用t[j - 1]来匹配” 的情况呢。这里大家要明确,我们求的是 s 中有多少个 t,而不是 求t中有多少个s,所以只考虑 s中删除元素的情况,即 不用s[i - 1]来匹配 的情况。
- 递推公式
dp[i][j] = dp[i - 1][j - 1] + dp[i - 1][j];和dp[i][j] = dp[i - 1][j];中可以看出dp[i][j]是从上方和左上方推导而来。那么dp[i][0]和dp[0][j]是一定要初始化 dp[i][0]表示:以i-1为结尾的s可以随便删除元素,出现空字符串的个数。那么dp[i][0]一定都是1,因为也就是把以i-1为结尾的s,删除所有元素,出现空字符串的个数就是1。dp[0][j]:空字符串s可以随便删除元素,出现以j-1为结尾的字符串t的个数。那么dp[0][j]一定都是0,s如论如何也变成不了t- 最后就要看一个特殊位置了,即:
dp[0][0]应该是多少。dp[0][0]应该是1,空字符串s,可以删除0个元素,变成空字符串t
以s:”baegg”,t:”bag”为例,推导dp数组状态如下
1 | class Solution: |
两个字符串的删除操作
给定两个单词 word1 和 word2,找到使得 word1 和 word2 相同所需的最小步数,每步可以删除任意一个字符串中的一个字符。示例:输入: “sea”, “eat”,输出: 2,解释: 第一步将”sea”变为”ea”,第二步将”eat”变为”ea”
方法一
- 这次是两个字符串可以相互删了
dp[i][j]:以i-1为结尾的字符串word1,和以j-1位结尾的字符串word2,想要达到相等,所需要删除元素的最少次数- 当word1[i - 1] 与 word2[j - 1]相同的时候,
dp[i][j] = dp[i - 1][j - 1] 当word1[i - 1] 与 word2[j - 1]不相同的时候,有三种情况
- 情况一:删word1[i - 1],最少操作次数为
dp[i - 1][j] + 1 - 情况二:删word2[j - 1],最少操作次数为
dp[i][j - 1] + 1 - 情况三:同时删word1[i - 1]和word2[j - 1],操作的最少次数为
dp[i - 1][j - 1] + 2 - 那最后当然是取最小值,所以当word1[i - 1] 与 word2[j - 1]不相同的时候,递推公式:
dp[i][j] = min({dp[i - 1][j - 1] + 2, dp[i - 1][j] + 1, dp[i][j - 1] + 1})
- 情况一:删word1[i - 1],最少操作次数为
dp[i][0]:word2为空字符串,以i-1为结尾的字符串word1要删除多少个元素,才能和word2相同呢,很明显dp[i][0] = i,dp[0][j]同理。- 从递推公式可以看出
dp[i][j]都是根据左上方、正上方、正左方推出来的。所以遍历的时候一定是从上到下,从左到右
以word1:”sea”,word2:”eat”为例,推导dp数组状态图如下

1 | class Solution: |
方法二
思路和动态规划:1143.最长公共子序列基本相同,只要求出两个字符串的最长公共子序列长度即可,那么除了最长公共子序列之外的字符都是必须删除的,最后用两个字符串的总长度减去两个最长公共子序列的长度就是删除的最少步数。
1 | class Solution { |
编辑距离
给你两个单词 word1 和 word2,请你计算出将 word1 转换成 word2 所使用的最少操作数 。你可以对一个单词进行如下三种操作:
- 插入一个字符
- 删除一个字符
- 替换一个字符
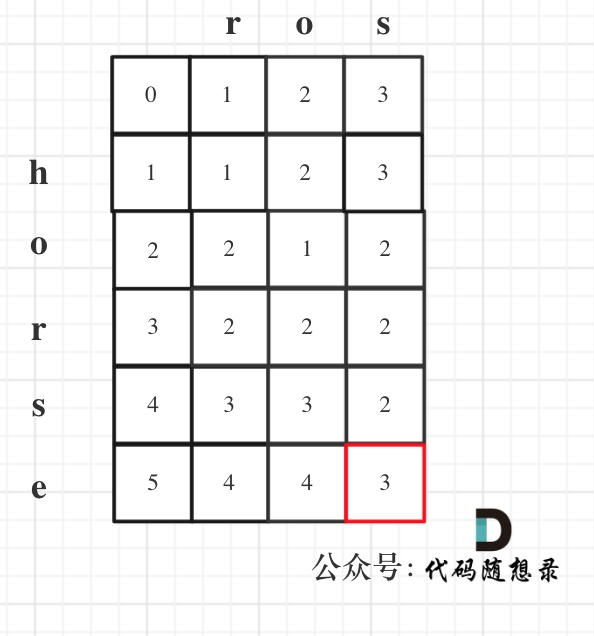
示例 1,输入:word1 = “horse”, word2 = “ros”, 输出:3,解释: horse -> rorse (将 ‘h’ 替换为 ‘r’) rorse -> rose (删除 ‘r’) rose -> ros (删除 ‘e’)
示例 2,输入:word1 = “intention”, word2 = “execution”,输出:5,解释: intention -> inention (删除 ‘t’) inention -> enention (将 ‘i’ 替换为 ‘e’) enention -> exention (将 ‘n’ 替换为 ‘x’) exention -> exection (将 ‘n’ 替换为 ‘c’) exection -> execution (插入 ‘u’)
dp[i][j]表示以下标i-1为结尾的字符串word1,和以下标j-1为结尾的字符串word2,最近编辑距离为dp[i][j]。在确定递推公式的时候,首先要考虑清楚编辑的几种操作,整理如下
1
2
3
4
5
6if (word1[i - 1] == word2[j - 1])
不操作
if (word1[i - 1] != word2[j - 1])
增
删
换if (word1[i - 1] == word2[j - 1])那么说明不用任何编辑,dp[i][j]就应该是dp[i - 1][j - 1],即dp[i][j] = dp[i - 1][j - 1]if (word1[i - 1] != word2[j - 1])- 操作一:word1删除一个元素,那么就是以下标i - 2为结尾的word1 与 j-1为结尾的word2的最近编辑距离 再加上一个操作。即
dp[i][j] = dp[i - 1][j] + 1 - 操作二:word2删除一个元素,那么就是以下标i - 1为结尾的word1 与 j-2为结尾的word2的最近编辑距离 再加上一个操作。即
dp[i][j] = dp[i][j - 1] + 1 - 怎么都是删除元素,添加元素去哪了。word2添加一个元素,相当于word1删除一个元素,例如
word1 = "ad" ,word2 = "a",word1删除元素'd'和word2添加一个元素'd',变成word1="a", word2="ad", 最终的操作数是一样 - 操作三:替换元素,
word1替换word1[i - 1],使其与word2[j - 1]相同,此时不用增删加元素。那么只需要一次替换的操作,就可以让 word1[i - 1] 和 word2[j - 1] 相同。所以dp[i][j] = dp[i - 1][j - 1] + 1
- 操作一:word1删除一个元素,那么就是以下标i - 2为结尾的word1 与 j-1为结尾的word2的最近编辑距离 再加上一个操作。即
综上,当
if (word1[i - 1] != word2[j - 1])时取最小的,即:dp[i][j] = min({dp[i - 1][j - 1], dp[i - 1][j], dp[i][j - 1]}) + 1
所以,递归公式代码如下:
1 | if (word1[i - 1] == word2[j - 1]) { |
dp[i][j]表示以下标i-1为结尾的字符串word1,和以下标j-1为结尾的字符串word2,最近编辑距离为dp[i][j]。
那么dp[i][0]和 dp[0][j]表示什么呢?
dp[i][0]:以下标i-1为结尾的字符串word1,和空字符串word2,最近编辑距离为dp[i][0]。那么dp[i][0]就应该是i,对word1里的元素全部做删除操作,即:dp[i][0] = i, 同理dp[0][j] = j
从如下四个递推公式,可以看出dp[i][j]是依赖左方,上方和左上方元素的
1 | dp[i][j] = dp[i - 1][j - 1] |
以示例1为例,输入:word1 = "horse", word2 = "ros"为例,dp矩阵状态图如下
1 | class Solution: |