背景
最近开始学习 Dify 源码,同时也会将里面的一些功能和 Langchain 中的技术方案做对比。希望可以得出不同的技术选型解决了什么样场景的问题,以及侧重点,优缺点等。
Dify 是一款开源的大语言模型(LLM) 应用开发平台。它融合了后端即服务(Backend as Service)和 LLMOps 的理念,使开发者可以快速搭建生产级的生成式 AI 应用。即使你是非技术人员,也能参与到 AI 应用的定义和数据运营过程中。
开发环境搭建
我们的目标是在本地搭建一套开发环境,接口使用本地的,但是前端页面,数据库,向量数据库,redis 等均使用容器的方式。以达到快速开发和调试后端接口的目的。
1 | git clone git@github.com:langgenius/dify.git |
安装依赖
1 | cd dify/api & pip install -r requirements.txt |
修改 docker/docker-compose.yaml 文件,将所有的端口都映射到宿主机,例如:
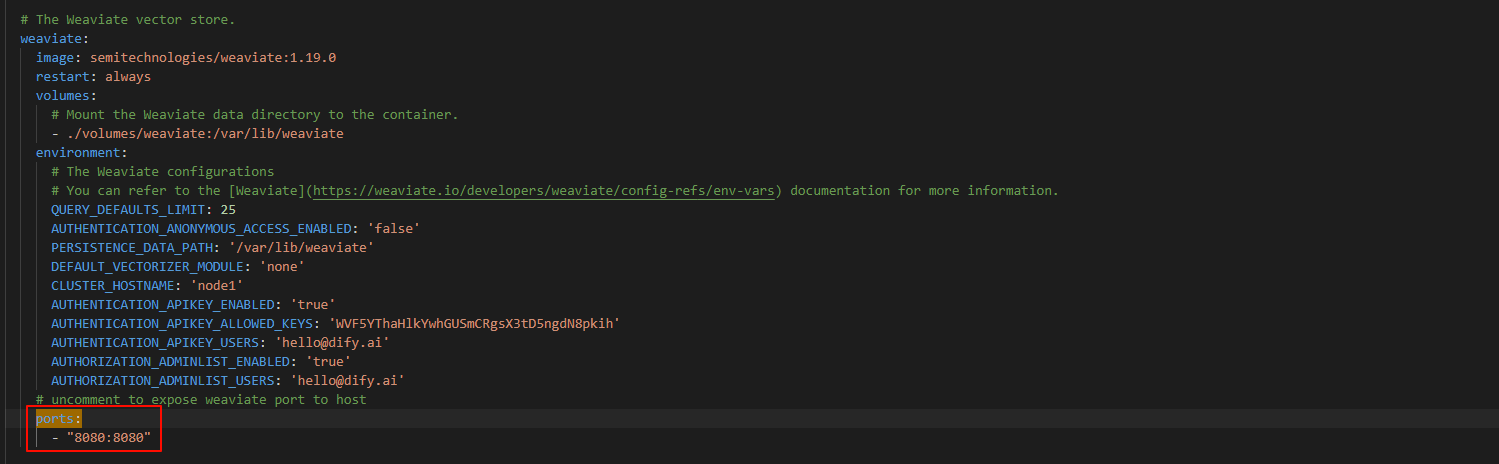
这里需要将 weaviate,nginx,dify-web,postgres,redis 的端口都映射到宿主机,就不一一举例了。还需将 dify-web 调用后端接口的地址修改一下,修改为我们地址启动的地址,例如:
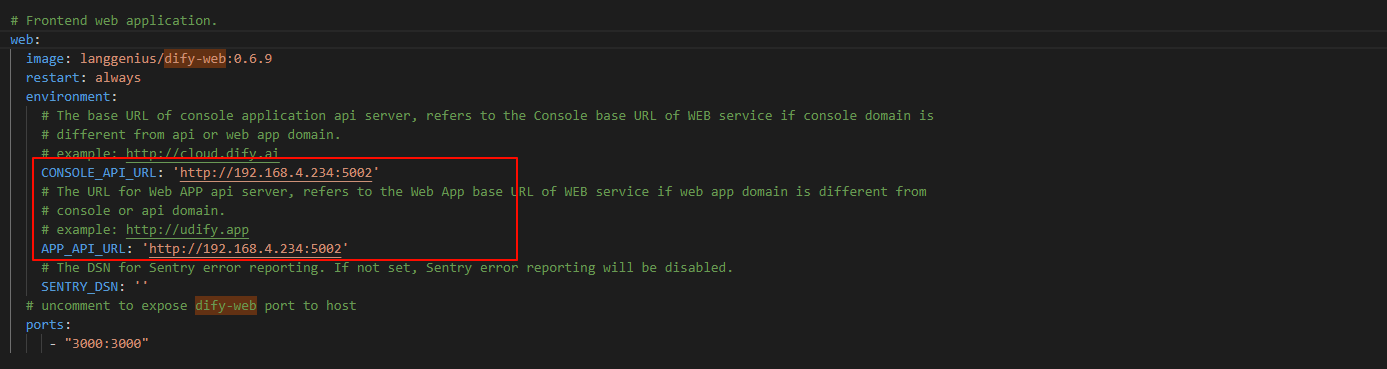
启动后端,运行 docker-compose,然后浏览器访问 http://localhost/apps 就成功啦!
数据源上传文本
接下来我们研究一下知识库的模块,想要创建一个知识库,第一步就是上传一些文档。
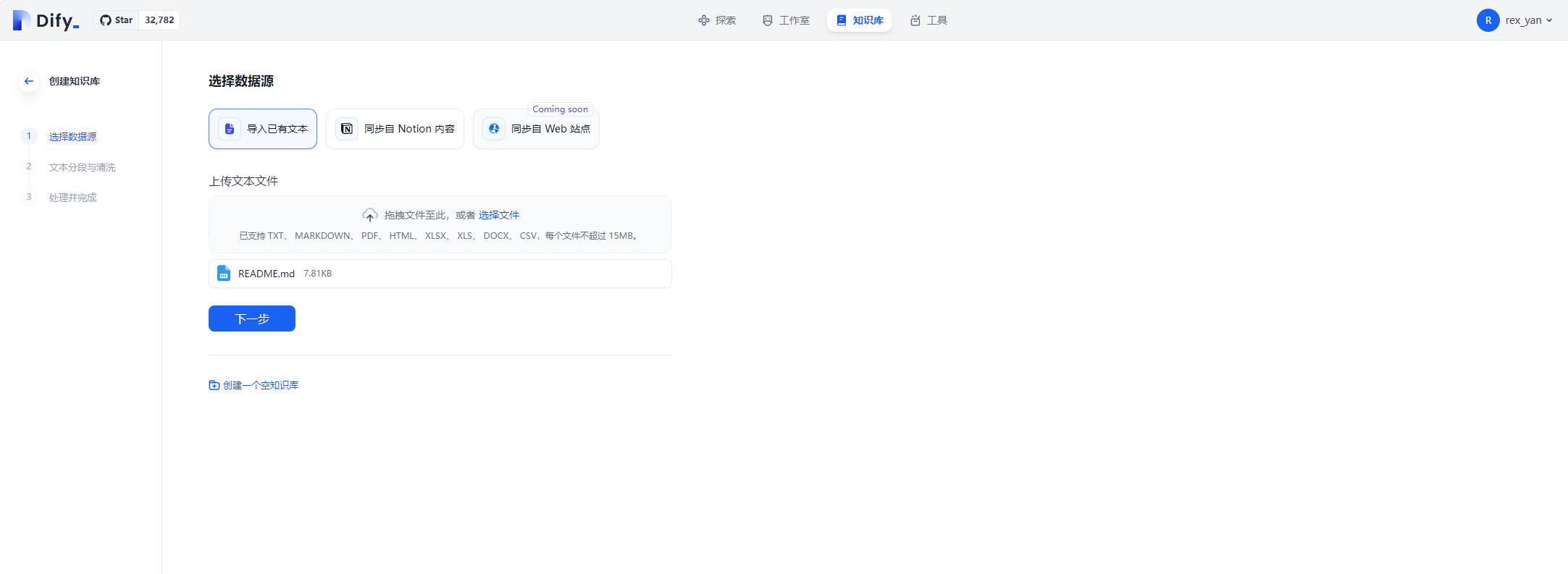
选择文件后会调用 /api/files/upload 接口,逻辑很简单。但需要注意这里的 storage 实例是通过配置文件设置的。在初始化时,就能确定是那种类型的 storage。默认使用 LocalStorage
1 | class Storage: |
文本分段与清洗
点击下一步后,会调用 datasets/indexing-estimate 接口,这个接口的作用是给出预计的 tokens 数量和分段的预览数据。其中核心的方法为 indexing_runner.indexing_estimate。方法中,会根据用户前端选择清洗规则创建一个 splitter,然后进行文档的拆分和 token 的估计。
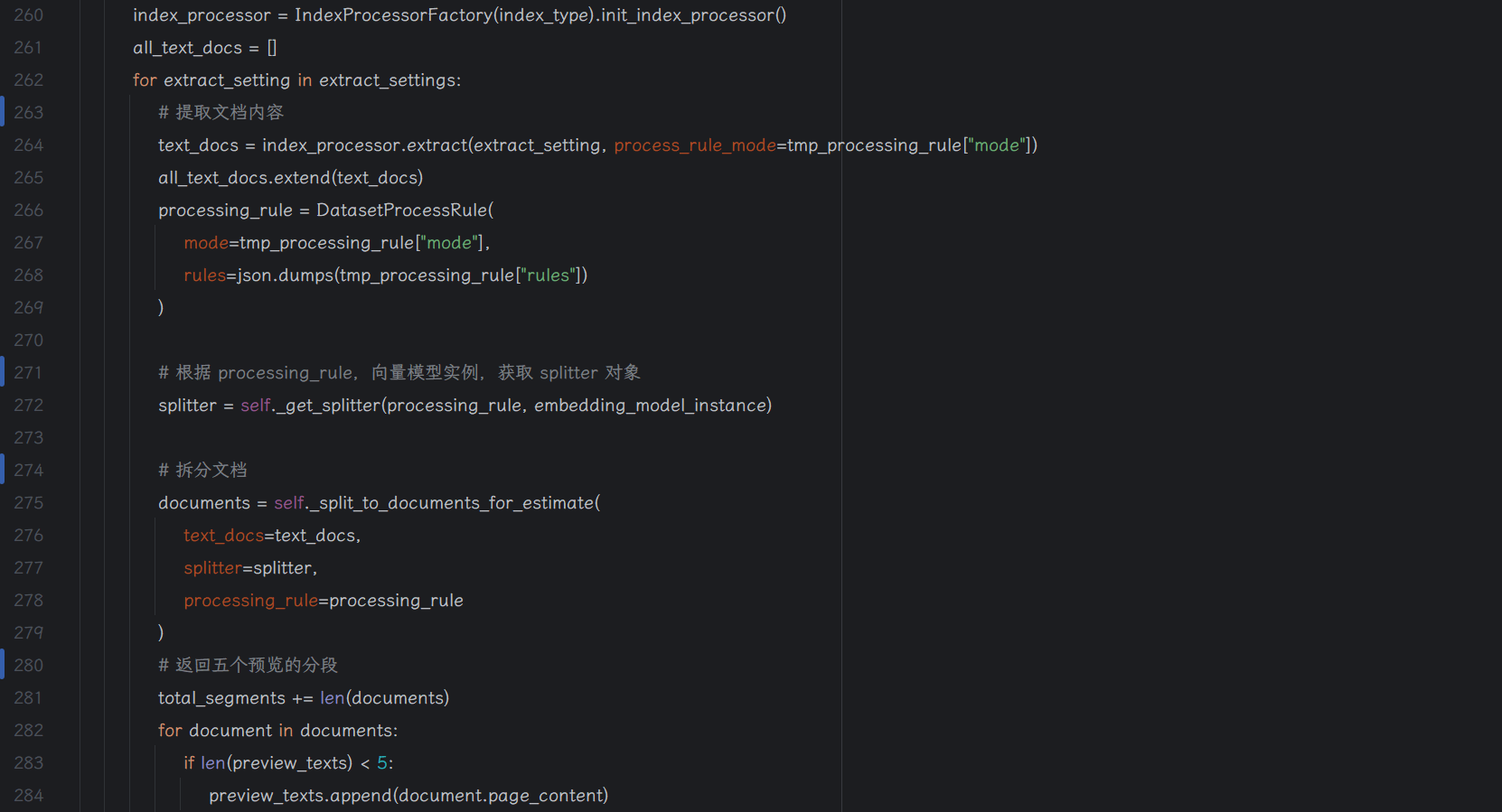
extract 方法按照业务有两种实现,一种是 ParagraphIndexProcessor(段落索引处理器)和 QAIndexProcessor(问答索引处理器)。每种 extract 实现里面,按照不同文件类型也有不同的实现,例如:非结构化数据,结构化数据,pdf,markdown,xlsx….
spliter 同样也有不同的实现,例如自定义的,换行,是否需要 chunk_overlap 等。
向量化方案
进入到文本分段与清洗阶段后,我们将分段设置设置为自动分段与清洗,索引方式选择高质量,检索方式因为我没有Rerank模型,所以这里就只选择向量检索,并且不需要 Rerank 模型。

点击保存并处理后,会调用 /console/api/datasets/init 接口,其中调用 save_document_without_dataset_id 方法
目标是创建一个 DataSet,需要用到 retrieval_model,collection_binding_id,embedding_model 等参数。之后会调用 save_document_with_dataset_id 方法,在里面会创建 dataset_process_rule。然后是循环上传的文件列表,执行 docuemnt 的创建或者更新。
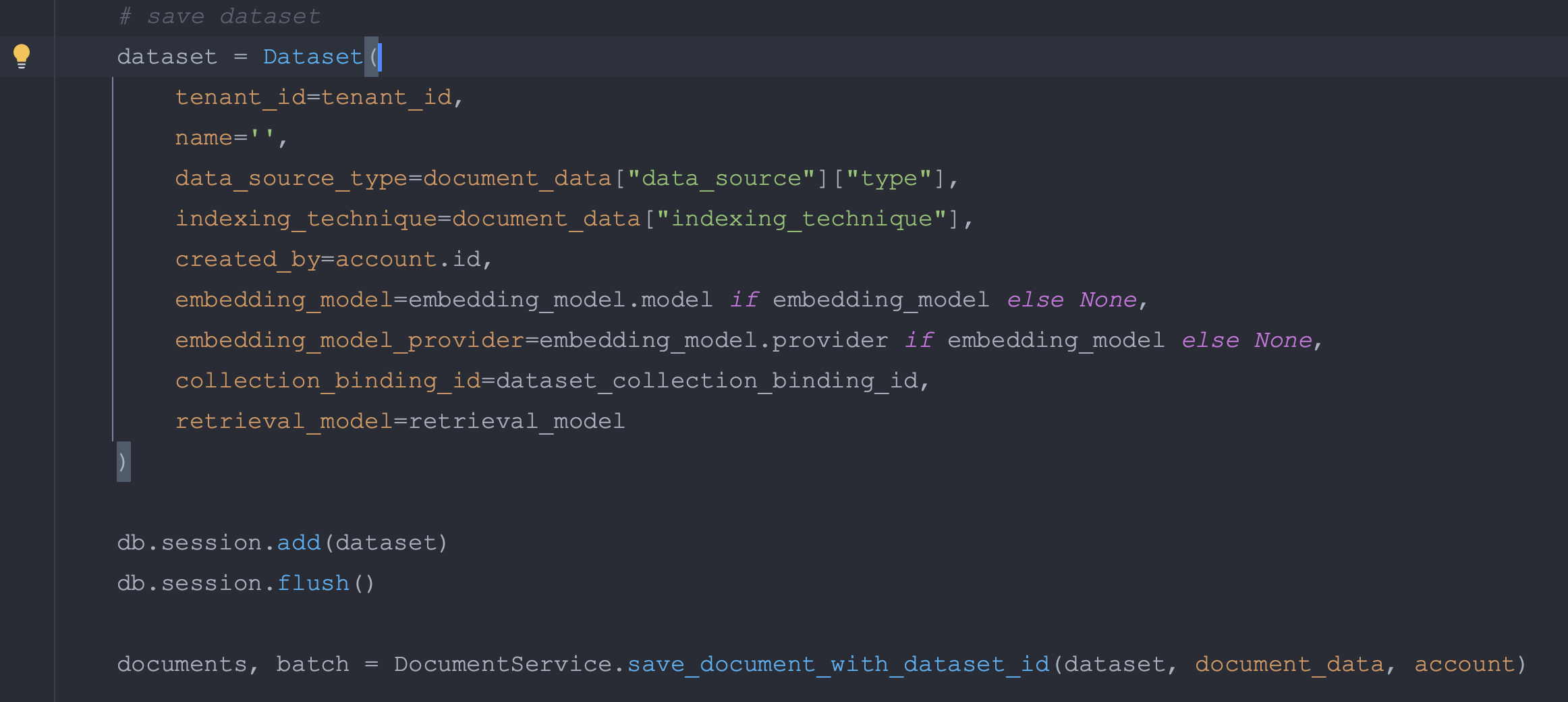
如果 document 不存在则创建一个新对象,如果存在则更新 document。判断 document 是否存在的条件是通过名称,dataset id,租户名等参数。
最终会得到两个列表,document_ids 和 duplicate_document_ids。分别存放了新增的 document 的 id 和 已经存在的 document 的 id。
最后将新建的 document 列表(document_ids)传入 document_indexing_task 异步任务中。
将更新的 document 列表(duplicate_document_ids)传入 duplicate_document_indexing_task 异步任务中
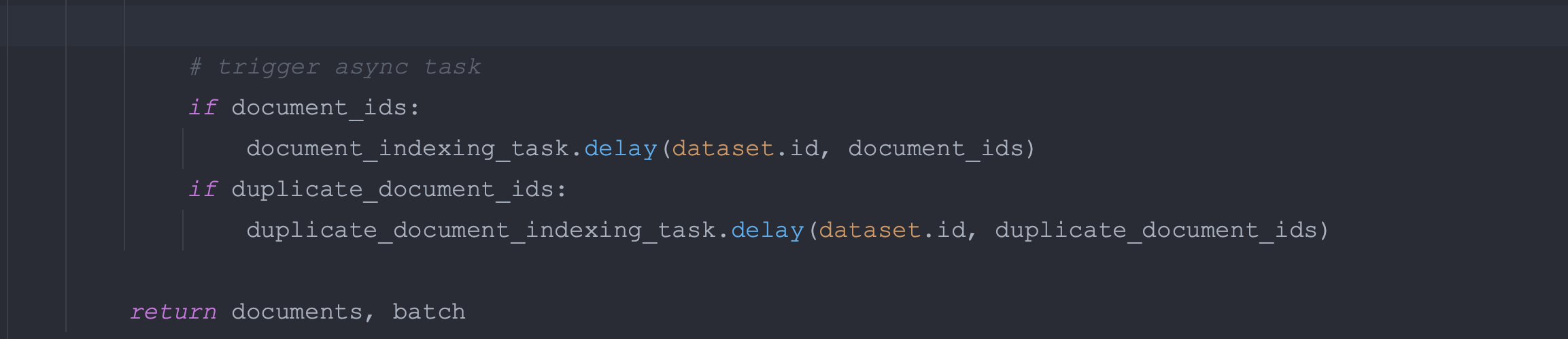
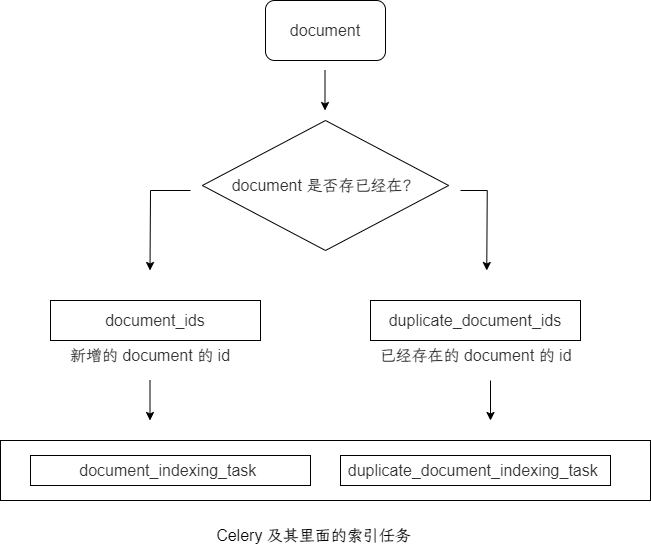
向量的获取,是在两个 Celery 的异步任务中执行的,并且使用了 Jieba 提取关键字,线程池获取向量,还涉及了向量的缓存等方案,其中涉及的内容和方法很多,后续更新在新的章节中。