概览
本篇文章,会先介绍 LangChain 中提供的索引管理方案。然后再分别介绍 Dify 中的新文档是如何进行索引的。
在细节及其疑惑部分,我们会介绍重复文档该如何处理,文档更新后又如何获取新的向量等。
最后还看看当使用 PGVector 存储向量时,Dify 中会存储哪些字段。
LangChain 中的索引管理
LangChain 在其文档中,介绍了一种叫做 RecordManager 的记录管理器来管理索引。文档详细的信息可以在此处查询到。它的工作原理为,在索引内容时,会为每个文档计算哈希值,并将以下信息存储在记录管理器中:
- 文档哈希(页面内容和元数据的哈希)
- 时间
- source id
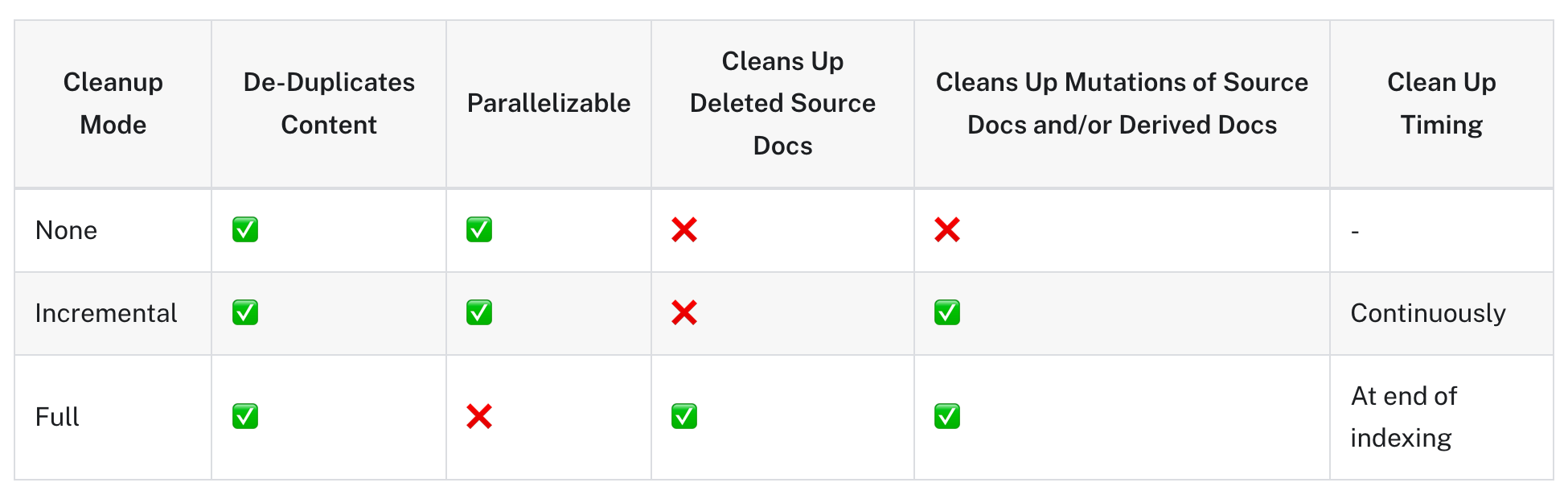
并且将文档索引到向量存储中时,提供了三种删除模式,分别为:
- None 模式: 此模式不会自动清理旧版本的内容;但是,它仍会进行内容重复数据删除。举例:当我进行三份相同文本进行索引时,最终结果只会有一份。且以前的数据不影响。
- incremental 模式:对相同文本再次索引时将会被跳过。但是如果对已经存在的索引进行更新,那么则会写入新版本,并删除所有共享同一 source 的旧版本。
- full 模式:任何未传递到索引函数且存在于向量存储中的文档都将被删除。也就是说只会保存当前我提交的,之前的都会被删除。
Dify 中的索引管理和 LangChain 中的 incremental 模式类似。接下来让我们共同揭秘一下细节。
Dify 中的文档索引任务
在上篇文章《 Dify开发环境搭建,数据上传及向量化方案》的末尾,我们提到了 Dify 的向量化方案是在异步任务 中完成的。因为篇幅太多,所以没有详细的介绍。本节我们就会详细的讲解一下这部分,这一部分执行的是 document_indexing_task 异步任务。了解了这一部分,那么对于接下来的文档重复如何处理?文档更新如何处理?就会很简单了。
异步任务传入 dataset_id 和未被索引过的 document_id 列表
根据传入的 dataset_id 获取 dataset 对象,根据传入的 document_ids,循环更新 Document 对象,更新状态为 parsing,更新处理的开始时间
因为是异步任务所以,传入的是 document 的 id,所以这里是需要重新取获取 document 的内容。需要调用 self._extract 方法提取文本,返回值为 list[Document],即一个 Document 的列表。并且将下一步的状态标记为 splitting
Document 还需要进一步的处理,为其加上一些元数据。这些元数据包括,doc_id,doc_hash。【doc_id 是 uuid,doc_hash 则是根据内容计算的 hash 值】
然后会清除 Document 对象的一些额外信息,例如空格,邮箱等,这些是用户可在前端进行选择的。
对于接下来的向量话方案来说,一个 Document 还是太大,所以需要进一步的进行拆分,将一个 Document 拆分为多个 DocumentSegment 对象。同时将 document 接下来的状态标记为 indexing,segment 的状态标记为 indexing
接下来就是创建一个线程,用于创建关键字索引。执行的方法为
self._process_keyword_index,在这个方法中先获取了dataset 对象,然后创建一个 Keyword 实例。Keyword.create 使用 Jieba分词 进行关键词的提取,并且将关键词保存到 document_segment 对象中。最后将关键词保存到数据库中,或者文件系统中。接下来创建一个线程池,池子的 max_workers 为10,线程一启动,就会先执行 self._process_chunk 预估大致会消耗的 token 的数量。然后创建对应的 Vector 实例,调用 create 方法创建 embeddings。
- 在创建 embeddings 的过程中,会根据每个 document.page_content 的hash值,使用的模型,provider 的名称来判断该段文件之前是否向量化过。如果没有向量化,那么获取到当前模型的 max_chunks,按照 max_chunks 拆分这个文本,得到每次需要向量化的 chunk 内容。得到向量化的结果后,会和文本的 hash 值进行绑定,最终存储在 Embedding 表中。会记录 模型名称,provider,hash值,pickle 序列化后的 embedding 值。如果已经向量化过了,那么直接从数据库中查询结果即可。
- 得到向量结果后(可能是新生成的,也可能是直接从数据库获取到以前的)需要把向量保存到向量数据库中。
以上就是整个新文档向量话的整个过程中,如果将上述详细步骤进行归类的话,分别可以归到以下几个阶段中:

初始化准备: 步骤1,步骤2。这一阶段的主要工作是一些前置工作的准备和处理
extract 阶段:步骤3。这一阶段的主要工作是提取内容得到 Document 列表。
transform阶段:步骤4,步骤5。这一阶段的工作是添加一些元数据和 Document 的清洗。
load segments 阶段:步骤6。这一阶段的工作是拆分 Document,得到 DocumentSegment。
load 阶段: 步骤7,步骤8,步骤9,步骤10。这一阶段的工作是启用一个线程进行 Keyword 的获取和 embedding。以及采用线程池的方式运行 document segment 的 embedding。
细节及其疑惑
重复的 document 如何处理?
上述介绍的其实是新的 document 的 embedding 步骤,执行的是 document_indexing_task 异步任务。对于重复的 Document,执行的是 duplicate_document_indexing_task 异步任务,步骤如下:
- 异步任务传入 dataset_id 和被索引过的 document_id 列表
- 根据 document_id,获取所有 DocumentSegment 对象的 index_node_id,得到一个 index_node_ids 列表
- 调用 index_processor.clean 方法,删除这些 index_node_id 在向量数据库中的数据
- 然后再在数据库中删除这些 segment
- 接下来就和 document_indexing_task 任务中的 extract 阶段接下来的一致了
总结下来就是多了一个删除旧数据的过程(删除向量数据库中的数据和后端缓存中的数据,其中后端的删除中,并没有删除Embedding表中的数据,只是删除了 DocumentSegment 记录)
document 更新如何处理?
执行的是 document_indexing_update_task 异步任务,步骤如下:
- 传入参数为 dataset_id,document_id。首先获取到 document 对象。
- 将 document indexing_status 状态标记为 parsing
- 查询 document 对应的 segments 列表,获取到所有的 index_node_id
- 调用 index_processor.clean(dataset, index_node_ids) 在向量数据库中删除这些数据
- 再在数据库中删除 segments 数据
- 最后重新实例化 IndexingRunner 对象,调用 indexing_runner.run([document]) 方法,重新将 document 向量化
向量数据库中都存了哪些数据?
这里以 PGVector 举例,看看在往里面插入 embedding 数据时,都保存了哪些字段和数据。
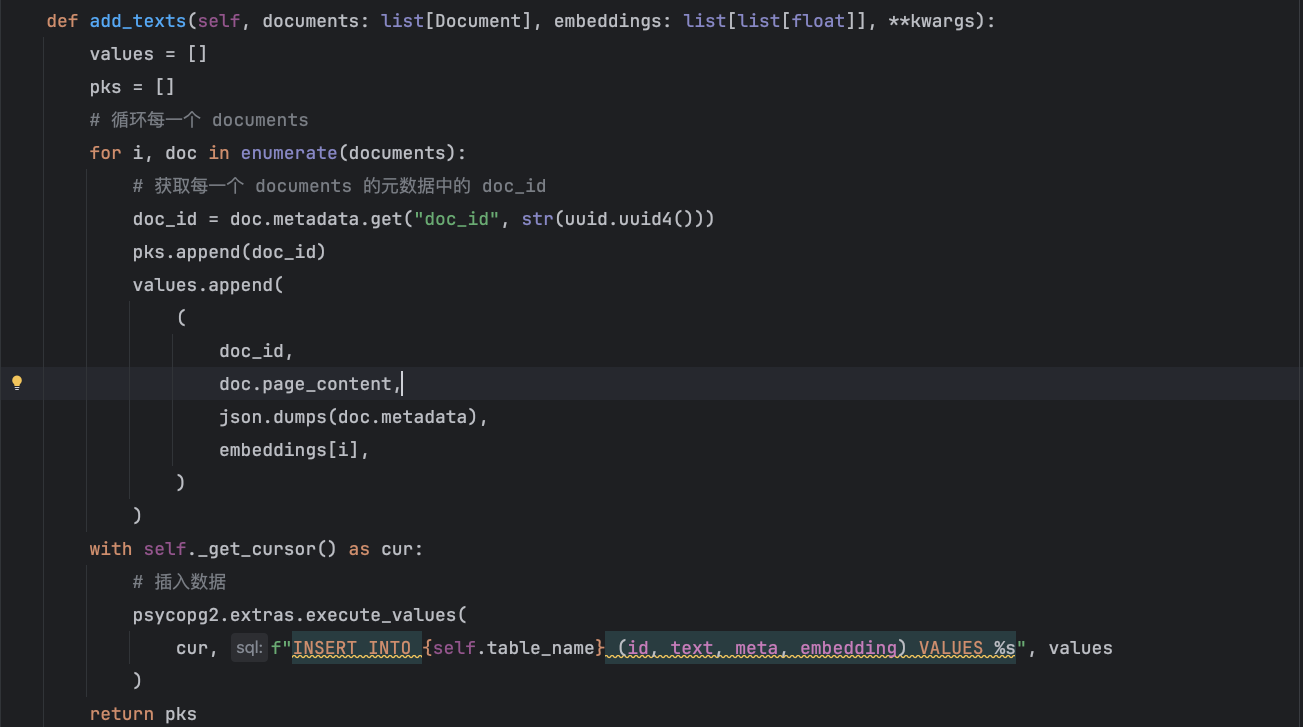
如上所示,当用 PostgreSQL 当作向量数据库时,会保存 doc_id,文本内容,元数据,向量数据这些内容。
元数据包含哪些字段
一个 Document 包含的内容如下,所以元数据包含 doc_id,doc_hash,document_id,dataset_id 等信息
1 | document = Document( |
在进行召回的时候,是怎么通过文本片段,定位到文档的
查询时,根据 top_k 和 score_threshold 定位到相关的文档,然后根据元数据中的相关 doc_id, document_id 等信息再次到数据库中查询到相关的文档信息。以下是 pgvector 查询相似向量的实现:
1 | def search_by_vector(self, query_vector: list[float], **kwargs: Any) -> list[Document]: |
上述 SQL 中, <=> 是什么, pgvector 还支持什么
计算余弦距离的函数,pgvector 还支持:
<->- L2 distance<#>- (negative) inner product<=>- cosine distance<+>- L1 distance (added in 0.7.0)
更多信息可参考:https://github.com/pgvector/pgvector
数据真实存储在 pg 中是什么样子的?
Dify 目前支持哪些向量数据库?
milvus , pgvecto_rs pgvector,qdrant, relyt, weaviate
总结
文章开头我们先介绍了 LangChain 使用 RecordManager 来管理索引。引入了 Dify 的索引管理类似于LangChain的incremental模式。
接下来我们详细的介绍了 Dify 中文档的索引任务。可以总结为 初始化准备,transform阶段,load segments 阶段 和 load 阶段。并且大致介绍了每个阶段的工作内容。
在细节及其疑惑章节中,我们讨论了重复的 document 如何处理,以及 document 更新如何处理,并且还看了当使用 PGVector 存储向量时,Dify 中会存储哪些字段。