模型只能看到 Token
token 不是单词,而是被称为子词的单词的一部分,这是一种介于单词和字母之间 的表示形式。直观地讲,一个 token 捕获了语言中最小的有意义的语义单元。
分词的四个步骤:1、接收要处理的文本。2、转换字符串(例如将大写字符转换 为小写)。3、将字符串拆分为token。4、将每个token映射到唯一标识符(唯一标识符通常是 一个整数,这会产生LLM可以理解的输出)
分词过程的最后一步是构建词汇表。模型的词汇表是指在训练过程中看到的 唯一token的总数,为模型选择词汇表涉及一系列权衡:词汇表越大,模型能成功处理的信息就越多,处理速度就越慢,存储空间占用就越多。词汇量是影响大型语言模型(LLM)大小的一个因素,因此讨论控制词汇量 的方法和权衡至关重要。我们将描述如何通过改变分词过程的行为来影响词汇量,以及如何影响模型的能力和准确性。
字节对编码
通常会使用一种名为字 节对编码(BPE)的算法将字符串分解成标记。由于找到最有效的子词集是一个计算成本高的任务,BPE使用启发式方法来走捷径。 它从将单个字母视为token开始,然后找到相邻字母对中最频繁出现的组合,并将 它们组合成子词token。该算法重复此过程多次,继续使用子词token,直到达到 某个阈值,词汇量“足够小”。
例如,在第一次遍历时,BPE算法检查英语中使用 的单个字母的频率,并发现字母“i”、“n”和“g”经常彼此靠近。在第一次遍 历中,BPE可能会观察到“n”和“g”一起出现的频率比“i”和“n”高,因此它 将生成i和ng这两个token。在后续的遍历中,它可能会根据这些字母组合的频率 与“ng”与其他字母或子词一起出现的频率,将这些token组合成ing。一旦 BPE达到其停止点,它将识别出“eating”和“drinking”等频繁出现的组合作 为单词。
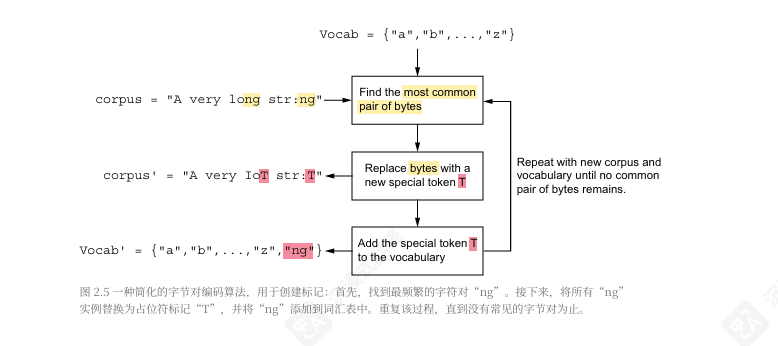
在BPE用于创建词汇表后,模型作者还会添加不直接表示单词部分的特殊token,但 为模型提供辅助信息。这种常见的例子包括“未知”token(通常表示为[UNK]), 如果分词器无法正确处理一个符号时使用,以及系统token[SYSTM],,用于区分模 型的内置提示和用户输入的数据,以及其他种类的风格标记。接受文本和图像输入 的多模态模型使用独特的token来告诉模型输入流在表示文本数据的字节和表示图 像数据的字节之间切换。
tiktoken
OpenAI决定在开发ChatGPT时使用BPE对文本进行编码,并将他们的分 词器作为开源软件包 tiktoken(https://github.com/openai/tiktoken)发布。然而,还有其他几种用于自动生成分词的算法和实现方式,包括Google开发的 WordPiece和SentencePiece算法。(Tokenizer - OpenAI API — 可在线尝试分词)
分词对成本的影响
LLM完成请求所需的时间以及用户每token的收费直接取决于分词器。因此, 使用分词器更高效的语言在经济上更有优势。以英语为基准,研究人员发现,当使 用ChatGPT和GPT‑4时,回答德语或意大利语用户查询的成本大约比英语高50%。 与英语差异更大的语言可能会产生更高的费用:Tumbuka和保加利亚语的成本超 过两倍,而东干语、奥里亚语、桑塔利语和山茶语处理成本超过英语的12倍。
总结
- 分词是大型语言模型通过将句子转换为 token 来理解文本的基本过程。
- token 是文本中最小的信息单元,代表内容。有时,它们对应于完整的单词,但 通常,它们代表单词的一部分或子词。
- 分词涉及规范化,这可能涉及将字符转换为小写或将 Unicode字符的字节编码转换为都可见的相同的字符使用的编码。
- 分词也涉及 segmentation,即将文本分割成单词或子词。像字节对编码(BPE)这样 的算法提供了一种机制,可以根据训练数据集中字母组合的统计出现频率自 动学习如何高效地分割文本。
- 构建分词器的结果称为一个词汇表,它是分词器可以用来表示其已处理文本 的唯一单词和子词集合
- 分词器的词汇表大小会影响LLM准确表示数据的能力,以及理解和预测文本 所需的存储和计算资源。
- 在LLM内部,词元使用数字表示。因此,没有对词元之间关系(如前缀和后缀)或两个词元共享相似字母集的理解。
- 为了支持特定领域的知识,自动训练的分词器可能会被增强(手动插入或维护一些 token),以提供对其应用重要的词元。
- 不理解单个字母或数字的分词器在算术运算或简单的文字游戏中会遇到问题。
输入如何变为输出
Transformer
Transformer 具有三种不同的标记预测方法
- 仅编码器模型:这些模型旨在创建可用于执行任务的知识表示——也就是说, 将输入编码为对算法更有用的数值表示。它们最容易被理解为将文本处理成机器学习算法更容易使用的形式。它们在科学研究中被广泛使用。著名的例 子包括BERT和RoBERTa
- 仅解码器模型:这些模型旨在生成文本。它们最好的理解方式是:它们接收 一个部分写好的文档,然后通过预测下一个标记来生成该文档的合理续写。 著名的例子包括OpenAI的GPT和Google的Gemini。
- 编码器-解码器模型:这些模型同样旨在生成文本。对于具有明确输入和输出序列的任务,编码器‑解码器模 型往往优于仅解码器模型。著名的例子包括T5和驱动Google翻译的算法。
从输入到输出的过程
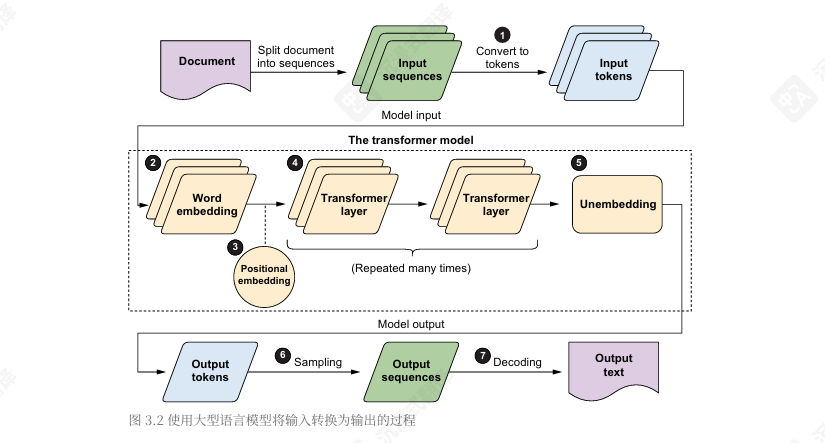
- 将文本转换为 token
- 将 token 进行 embedding
- 向每个 embedding 添加信息,以捕获每个 Token 在输入文本中的位置
- 将数据通过一个transformer层(重复L次)
- 应用 unembedding 获取可能产生良好响应的 token
- 从可能的 token 列表中采样,以生成单个响应
- 将响应中的 token 解码为实际文本
嵌入层
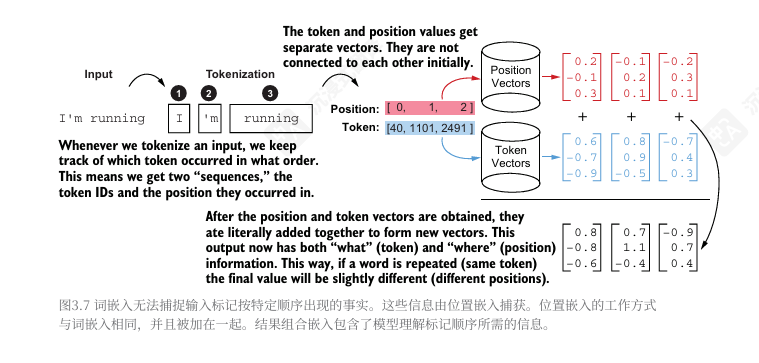
大型语言模型(LLM)的术语中,用于表示 token 的数字列表被称为 embeddings。你可以将 embeddings 视为一个浮点值数组或列表。作为简称,我们将此类数组称为向量。向量中的每个位置称为一个维度。
embedding 层生成两种不同的 embedding 。首先,它创建一个词embedding 来捕获标记的含义, 其次,它生成一个位置embedding 来捕获标记在序列中的位置。二者被加在一起。结果embedding 包含了模型理解 Token 顺序所需的信息。
Transformer层
query—query 是从embedding 层来的向量,表示你在寻找的内容
key—key 向量代表与查询配对的可能的答案。
value—每个key都有一个相应的value向量,当query和key匹配时,返回的实际value。
这种概念对应于 Python 中dict或字典对象的行为。你通过键在字典中查找一个项,以便然后创建一些有用的输出。区别在于转换器是模糊的。不是我们在查找单个键,而是我们在评估所有键,根据它们与查询的相似程度进行加权。
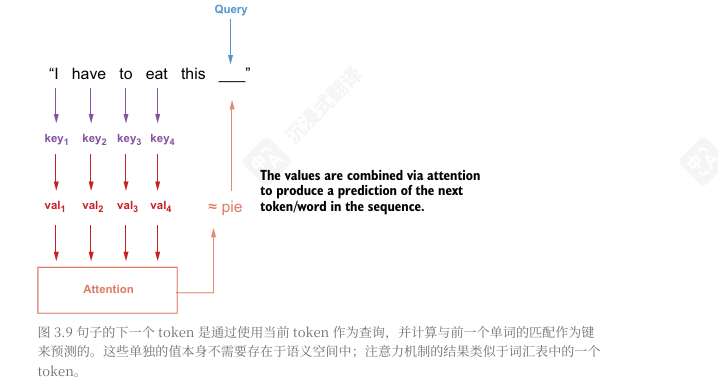
句子的下一个token是通过使用当前token作为查询,并计算与前一个单词的匹配作为键来预测的
Unembedding 层
将 Transformer 使用的向量表示转换为特定的输出token,以便我们最终可以返回与该token对应的文本。这种输出生成过程也称为解码,因为我们解码Transformer向量表示为一段输出文本。
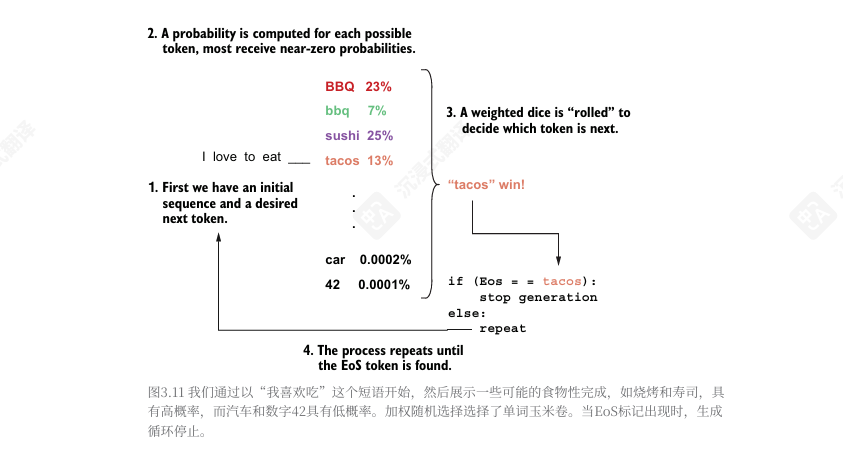
当模型生成一个新 token 时, EoS token 是它可以生成的选项之一。如果生成了EoS,我们知道是时候停止循环并将完整文本返回给用户了。如果您的模型进入不良状态并无法生成EoS token ,保留一个最大生成限制也是一个好主意。
大模型如何计算下一个 token:
对于词汇表中的每个token,计算每个token成为下一个被选中token的概率。
根据计算出的概率随机选择一个token。
总结
- 虽然大型语言模型使用token作为其语义意义的基本单元,但它们是在模型中用 embedding 向量而不是字符串进行数学表示。这些embedding 向量可以捕获关 于邻近性、差异性、反义词和其他语言描述属性的关系
- 位置和词序对Transformer 来说并非自然存在,而是通过另一个表示相对位置的向量获得。模型可以通过添加位置和词嵌入向量来表示词序。
- Transformer 层充当一种模糊字典,对近似匹配返回近似答案。这种模糊过程称为注意力,并使用query、key和value作为类似于Python字典中键和值的类比。
- ChatGPT 是一种仅解码器转换器的例子,但仅编码器转换器和编码器‑解码器转换器也存在。仅解码器转换器在生成文本方面表现最佳,但其他类型的 转换器在其他任务上可能更好
- LLMs是自回归的,这意味着它们递归地工作。在每一步中,所有先前生成的 token 都会被输入到模型中以获取下一个token 。简单来说,自回归模型使用先前的东西来预测下一个东西。
- 任何 Transformer 的输出都不是 token;相反,输出是每个 token 的概率。 选择一个特定的 token 被称为 unembedding 或sampling,并且包含一些随机性。 随机性的强度可以控制,从而产生更真实或不太真实的输出、更具创意或更 独特的输出,或更一致的输出。大多数LLM都有一个合理的随机性默认阈值, 但您可能需要根据不同的用途更改它。
LLM 如何学习
梯度下降是所有现代深度学习算法的关键。当行业从业者提到梯度下降时,他们 隐含地指的是训练过程中的两个关键要素。第一个被称为损失函数,第二个是计算梯度,这些是告诉你如何调整神经网络参数以便损失函数以特定方式产生结果的测量值。你可以将这些视为两个高级组件:
- 损失函数:你需要一个单一的数值分数来计算你的算法表现有多差。
- 梯度下降:你需要一个机械过程来调整算法内部的数值,使损失函数的分数尽可能小。
拥有损失函数是执行梯度下降的前提。损失函数客观地告诉你执行任务的糟糕程 度。梯度下降是我们用来找出如何调整神经网络参数以减少所产生损失的过程。 这是通过使用损失函数比较输入的训练数据和神经网络的实际与预期输出来完成 的。在这种情况下,梯度是你需要改变神经网络参数的方向和量,以减少损失函 数测量的误差量。梯度下降向我们展示了如何“稍微”调整神经网络的所有参数, 以改善其性能并减少预期输出与实际输出之间的差异。
每次应用梯度下降时,我们都会创建一个新的、略有不同的网络。由于变化 很小,这个过程必须执行数十亿次。这样,所有的小变化累积起来,在整体网络中产生更显著、更有意义的变化。
梯度下降是一个反复应用且没有偏差的数学过程。它不能保证会成功或找到最佳甚 至一个好的解决方案。
总结
- 深度学习需要一个损失/奖励函数,该函数专门量化算法在做出预测方面的表现有多差
- 这个损失/奖励函数应该设计为与算法在现实生活中要实现的整体目标相关联。
- 梯度下降涉及逐步使用损失/奖励函数来改变网络的参数
- LLMs通过预测下一个词元来训练模仿人类文本。这项任务足够具体,可以 训练模型来执行它,但它与推理等高级目标并不完全相关
- LLMs在与其训练数据中常见的、重复的任务相似的任务上表现最佳,但当任务足够 新颖时,它们会失败