触发入口
Dify 的工作流运行在线程中,其中支持多个分支的并行运行。工作流运行逻辑核心代码在 api/core/workflow/graph_engine/graph_engine.py文件中。GraphEngine中有以下方法:
run执行工作流图_run执行工作流节点的核心方法_run_node执行单个工作流节点_run_parallel_branches并行执行多个分支_run_parallel_node在独立线程中执行单个并行分支_release_thread释放线程池资源_is_timed_out_handle_continue_on_errorcreate_copy
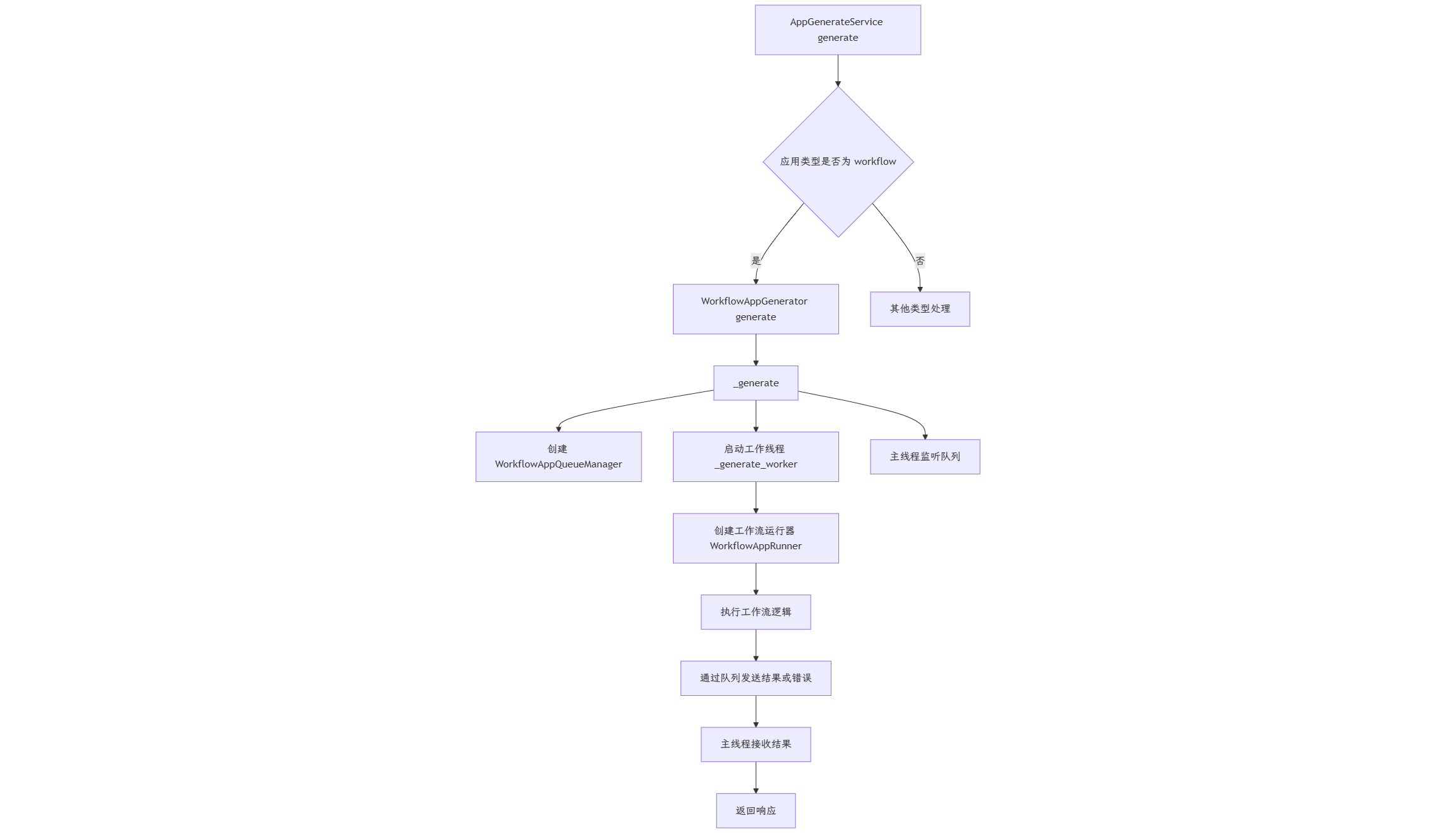
工作流的调用流程和其他类型的差不多,都是在 AppGenerateService 类中的 generate方法中进行判断和分发,当 App 的类型为 workflow 时,就会调用 WorkflowAppGenerator().generate 方法,进入到工作流的分支,在该方法中,都在准备整个工作流的参数,最后调用了 _generate 方法。
_generate 方法是实际执行工作流生成的核心方法,创建队列管理器、启动工作线程,并处理响应的转换和返回。采用多线程架构,主线程处理响应,工作线程执行工作流。
- 主线程: 处理用户请求和响应,保持请求上下文
- 工作线程: 执行实际的工作流逻辑,避免阻塞主线程(该线程执行了
_generate_worker方法) - 队列管理器: 负责线程间通信,传递执行结果和错误信息(
WorkflowAppQueueManager)
_generate_worker 方法在独立线程中执行实际的工作流运行任务。创建工作流运行实例(WorkflowAppRunner),处理各种异常情况,并通过队列管理器向主线程发送执行结果和错误信息。采用线程隔离的设计,避免长时间运行的工作流阻塞主请求线程。
三种运行模式
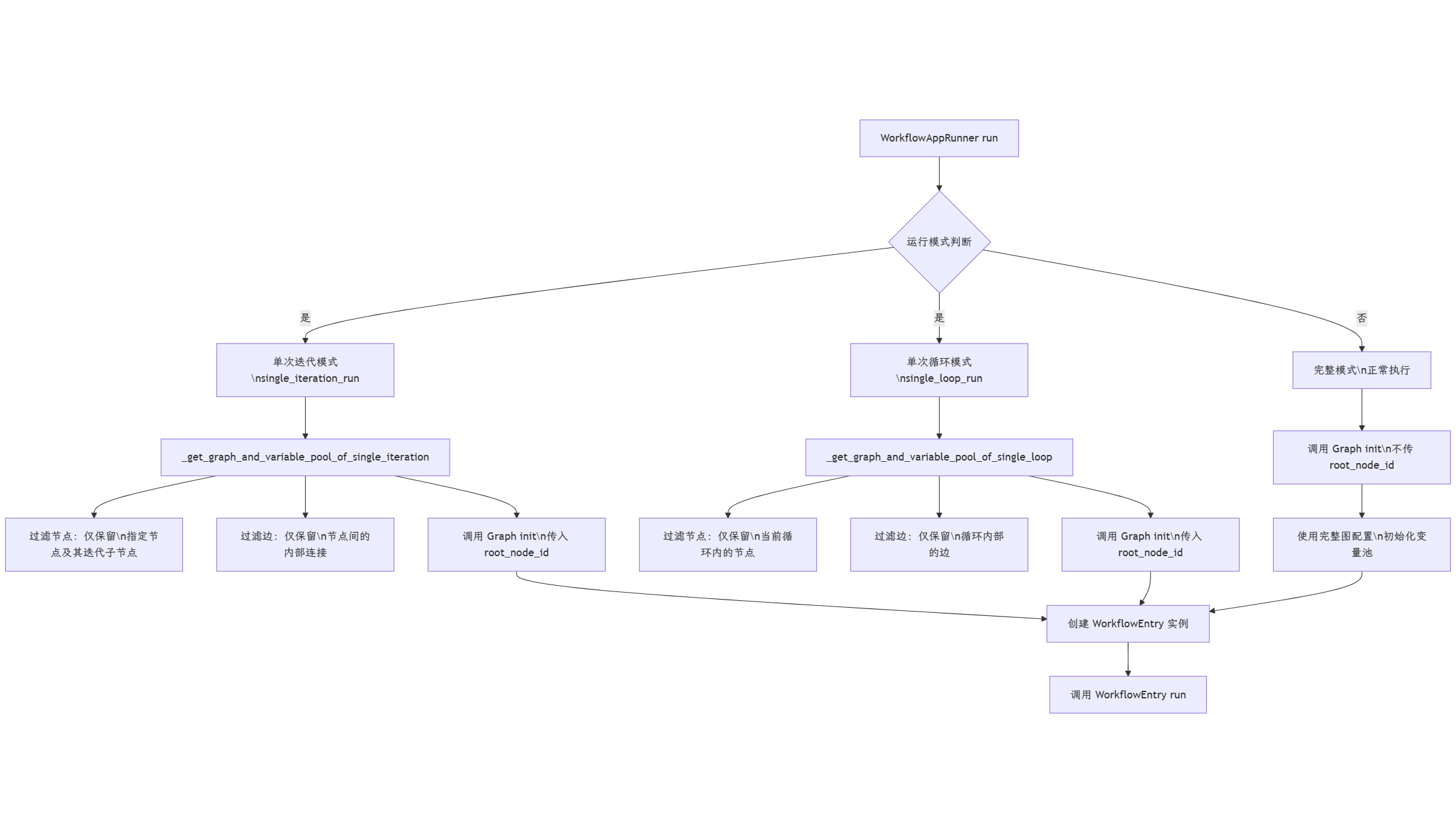
以上就完成了工作流和 API 请求的解耦,工作流的运行将在 WorkflowAppRunner 的 run 方法中进行。在这里面,支持了工作流运行的三种模式:
- 单次迭代:用于调试模式下的单个节点执行,通过
single_iteration_run参数指定要执行的节点,仅执行指定节点,不执行整个工作流 - 单次循环:用于调试模式下的循环节点执行,通过
single_loop_run参数指定要执行的循环节点,专门处理包含循环逻辑的节点 - 完整模式:正常的工作流执行模式,执行整个工作流的所有节点,包含完整的变量池初始化
WorkflowAppRunner 的 run 方法中,创建了工作流Graph结构,创建WorkflowEntry实例,然后调用 WorkflowEntry 实例的 run 方法。这里面的逻辑就比较复杂了,既区分了三种运行模型,又需要创建Graph结构。那我们来看看不同模式下的 Graph结构是如何创建的吧。
如果是单次迭代运行,调用 _get_graph_and_variable_pool_of_single_iteration方法获取对应的图和变量池,因为是单次迭代,所以在该方法中,过滤出只属于该迭代的节点和边,并初始化变量池
1 | # 过滤出只属于当前迭代的节点 |
1 | # 过滤出只属于当前迭代的边 |
初始化 Graph 时,将根节点设置为本次运行的单个节点,如此就完成了单迭代节点的初始化。
1 | # 初始化图对象,设置根节点 |
如果是单次循环运行,调用 _get_graph_and_variable_pool_of_single_loop 方法获取对应的图和变量池,步骤和上述是差不多的,只不过其中只过滤出属于当前循环的节点,只过滤出属于当前循环的边。
如果是完整工作流执行模式,则在调用Graph.init 方法时,不传入 root_node_id
单/并行分支
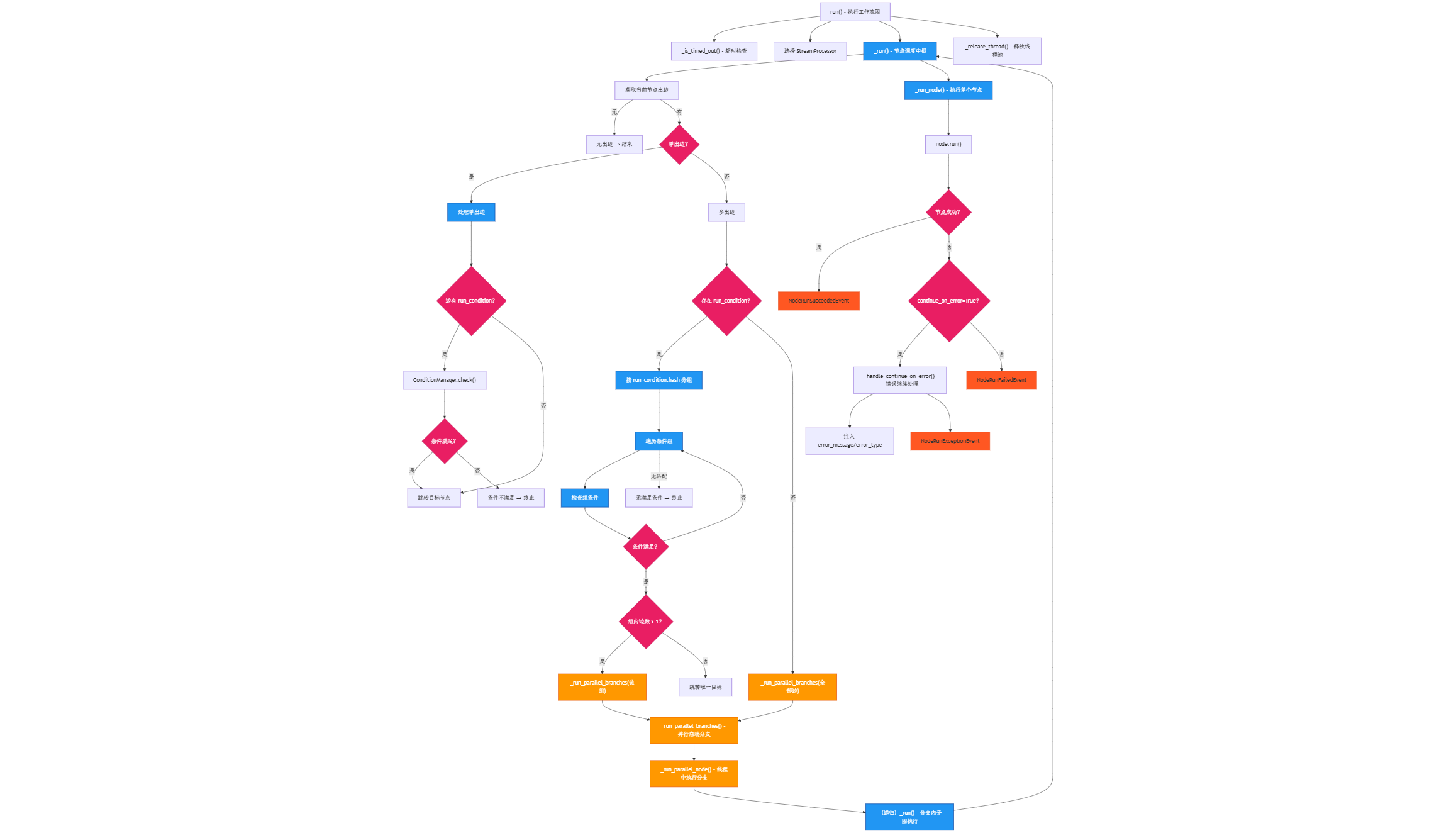
上述只是工作流三种运行模式的区分,下面来看看工作流的核心运行流程。上述流程中调用了 WorkflowEntry.run 方法,在其中紧接着调用了 graph_engine.run() 方法来触发工作流,其中工作流执行采用分层架构
run方法作为入口点,负责整体执行流程控制_run方法处理节点序列执行、条件分支和并行分支_run_node方法执行单个节点的具体逻辑
这里面涉及到运行单个分支,并行分支的情况(无依赖的分支节点是并行的),我们来区分看待:
单个分支执行详细过程
- 节点遍历: 按照图的边关系顺序执行节点
- 条件判断: 检查边的运行条件,决定执行路径
- 节点执行: 调用
_run_node()执行单个节点逻辑 - 状态传递: 将节点输出添加到变量池,供后续节点使用
- 事件发布: 实时发布节点执行状态事件
并行分支执行详细过程
- 分支识别: 在
_run()方法中检测到多个出边且无运行条件时,识别为并行分支 - 线程池分配: 使用
GraphEngineThreadPool为每个分支分配独立线程 - 分支启动: 调用
_run_parallel_branches()启动所有并行分支 - 事件收集: 通过队列收集各分支的执行事件,确保事件顺序正确
- 分支同步: 等待所有分支执行完成,收集汇聚节点ID
- 结果合并: 继续执行汇聚节点后的节点序列
_run_node() 是调用每个节点的入口,在其中调用了每个节点的 run 方法,如此就完成了每个节点的执行。
1 | while should_continue_retry and retries <= max_retries: |